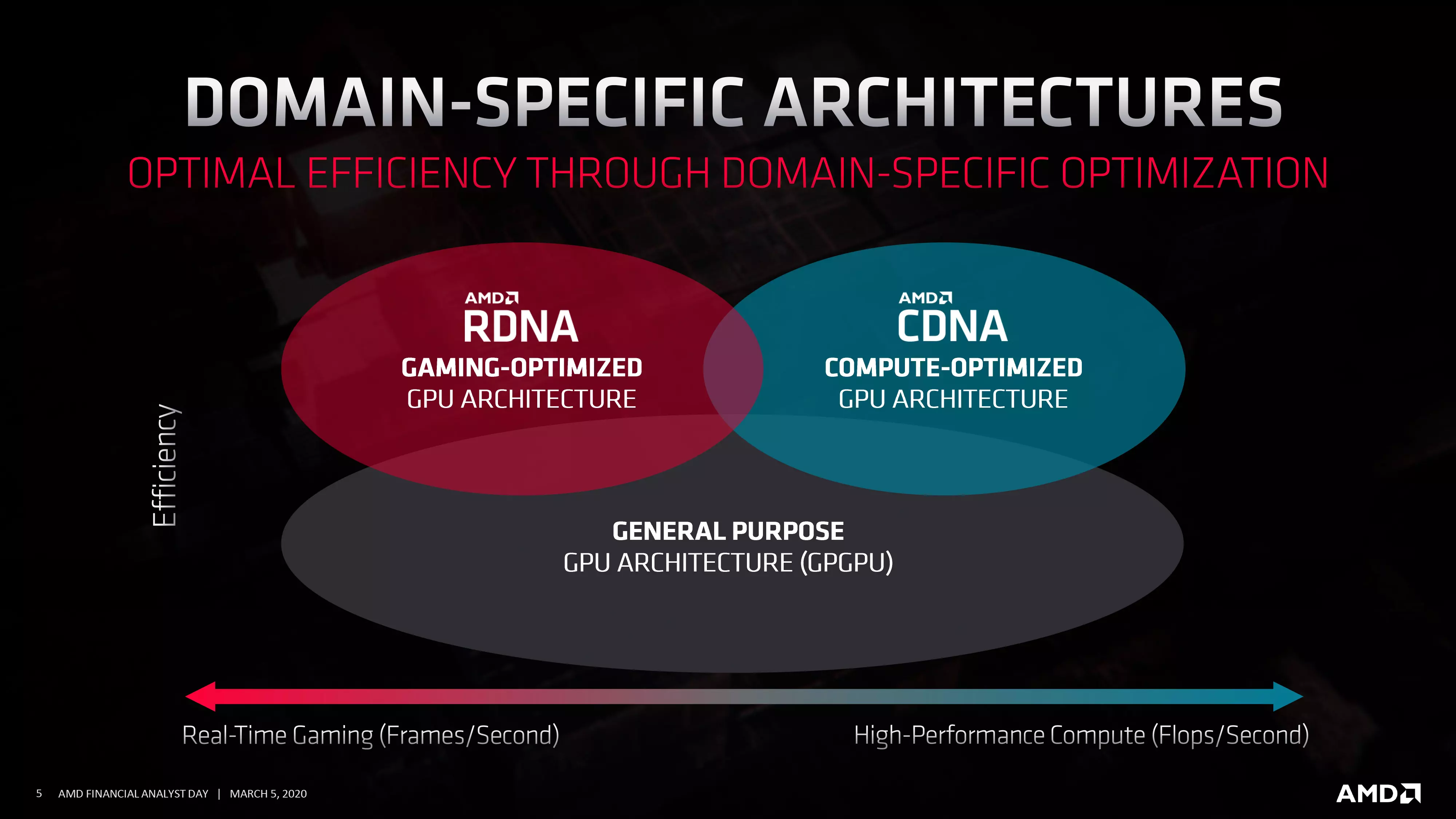
AMD hat im Hintergrund einige sehr große Veränderungen in Bezug auf die RDNA- und CDNA-Architektur vorzunehmen. Erstere wird die Grundlage für Consumer-Grafikkarten und prozessorintegrierte Grafikcontroller sein, während letztere ausschließlich in KI- und HPC-Beschleunigern für den Rechenzentrumsmarkt zum Einsatz kommen wird - beide sind für die Bedürfnisse ihrer jeweiligen Marktsegmente optimiert. Die beiden Architekturen haben sich seit 2019 entwickelt, als AMD die GCN-Architektur hinter sich ließ und beschloss, zu einem Modell mit zwei Architekturen überzugehen, da man damals glaubte, dass dies die richtige Richtung sei und es einfacher wäre, beide Bereiche mit einer spezialisierten Architektur zu bedienen. Gleichzeitig verwendet Nvidia seit langem die einheitliche CUDA-Architektur für alles, von Gaming-Grafikkarten über Allzweck-Beschleuniger bis hin zu KI-Beschleunigern, und diese Strategie hat sich bewährt, da sie nun die wichtigsten Marktsegmente dominieren.
Auf der IFA 2024 verriet Jack Huynh, Vice President und General Manager der Computing and Graphics Business Group von AMD, einige überraschende und interessante Details darüber, wie das AMD-Team die Zukunft der Märkte für Gamer-Grafikkarten und KI-Beschleuniger sieht. Die RDNA- und CDNA-Architekturen scheinen die Erwartungen nicht erfüllt zu haben, da sie in beide Richtungen schwierig zu entwickeln sind und die Arbeit der Softwareentwickler nicht gerade erleichtern. Daher wurde beschlossen, die CDNA- und RDNA-Architekturen in nicht allzu ferner Zukunft zu einer einzigen Architektur zusammenzufassen und diese einzige Lösung einfach UDNA zu nennen. Sobald dies geschehen ist, werden die Produkte für den Verbraucher- und den Rechenzentrumsmarkt dieselbe Architektur nutzen, was eine gute Nachricht ist, da sie dadurch besser mit der CUDA-Architektur von Nvidia konkurrieren können, die seit 18 Jahren auf dem Markt ist.
Er gab auch zu, dass das Entwicklungsteam an der RDNA-Front einige Fehler gemacht hat: In Fällen, in denen die Speicherhierarchie geändert wurde, sind einige der Optimierungen in den Papierkorb gewandert. Sie wollen das nicht mehr tun, sondern eine Architektur, die die verschiedenen Segmente auf konsistente Weise bedient, und sie wollen auch volle Abwärts- und Vorwärtskompatibilität zwischen den Architekturen sicherstellen. Das funktioniert an der Xbox-Front, es erfordert zwar ein fortschrittliches Design, aber es ist machbar. An der RDNA- und CDNA-Front wird dies eine Menge Arbeit für die Entwicklungsteams bedeuten, aber es ist der einzige Weg, die Vision zu erreichen.
Man möchte, dass sich immer mehr Entwickler für die neue AMD-Architektur entscheiden: erst Tausende, dann Zehntausende, dann Hunderttausende, dann Millionen. Die CUDA-Architektur, die intern bei Nvidia entwickelt wird, hat etwa 4 Millionen Entwickler auf dem Markt, was eine beeindruckende Zahl ist, die AMD im Laufe der Zeit gerne erreichen würde.
Als man sich entschied, die Architekturen zu trennen, wollte man beide Teile kurzfristig mikrooptimieren, aber jetzt besteht die Notwendigkeit, sie wieder zu vereinheitlichen, um jedes Marktsegment effektiver zu bedienen. Leider wurde nicht erwähnt, wie viele Architekturgenerationen dies genau erfordern wird. Der Manager sprach lediglich von einer Strategie, die er als gut bezeichnete, ohne jedoch näher darauf einzugehen, was dies genau bedeutet. Sicher ist, dass man davon ausgeht, dass die Entwickler mit der Veränderung zufrieden sein werden, aber es muss der richtige Zeitpunkt für die Veränderung gefunden werden - man kann ja auch nicht die Triebwerke eines Flugzeugs wechseln, wenn es in der Luft ist.
Die Umstellung von CDNA auf RDNA scheint die Erwartungen nicht erfüllt zu haben, und mit dem Aufkommen von KI im Consumer-Bereich beginnen RDNA-basierte Grafikkarten, die KI-Beschleunigung zu vermissen. In RDNA 3-basierten Produkten kann auf FP16-Einheiten über den WMMA-Befehlssatz mit einem gewissen Optimierungsgrad zugegriffen werden, während in RDNA 2 solche Aufgaben von GPU-Stream-Einheiten durchgeführt werden können. Im Vergleich dazu hat Nvidia seit der Einführung der RTX-Serie im Jahr 2018 Tensor-Kerne für die KI-Beschleunigung zur Verfügung, die in den letzten Jahren immer leistungsfähiger geworden sind. Mit der Verschmelzung der CDNA- und RDNA-Architekturen könnten auch Produkte auf dem Client-Markt die von der CDNA-Architektur bekannten KI-Beschleunigungseinheiten erhalten, die mit der zunehmenden Verbreitung von KI zu einer immer wichtigeren Komponente werden könnten.
Es gibt noch keine Neuigkeiten über die Ankunft der UDNA-Architektur, nur dass immer drei Architekturen im Voraus geplant sind. RDNA 4 ist noch nicht betroffen, aber RDNA 5 und RDNA 6 könnten betroffen sein, aber mehr wird später bekannt gegeben. Die einheitliche Architektur scheint auf jeden Fall die richtige Strategie zu sein. Die einzige Frage ist, wie schnell die Arbeit erledigt sein wird und wie der Markt reagieren wird, da Nvidias CUDA-Ökosystem derzeit das dominierende ist und es schwer ist, es zu entthronen, da es in der Branche so fest verankert ist.
