
Nvidia hat eine extrem starke Position auf dem Markt für KI-Beschleuniger, dank seiner GPU-basierten Ampere- und Hopper-Beschleuniger, die eine enorme Leistung bieten und sich großer Beliebtheit erfreuen, was das Unternehmen quasi zum Dominator in diesem Segment macht. Es gab bereits Gerüchte, dass die auf der Blackwell-Architektur basierenden KI-Beschleuniger bald kommen würden, die eine enorme Leistung bieten könnten, und diese wurden auf der gestrigen GTC 2024 vorgestellt, wenn auch nur teilweise, da der Hersteller nicht alle Schüsse bei einer formellen Präsentation abfeuerte und es noch viele Fragen zu beantworten gab.

Es ist kein Geheimnis, dass die Blackwell-Architektur auf zwei Hauptprodukten aufbaut: dem B200-Grafikprozessor und dem GB200-Superchip, der aus zwei B200-Grafikprozessoren und einem ARM-basierten Nvidia Grace-Prozessor besteht. Im Vergleich zum aktuellen Hopper H100, der die Spitze von Nvidias KI-Angebot darstellt, kann der B200 bei Deduktionsaufgaben bis zu fünfmal schneller sein, was keine geringe Verbesserung darstellt. Gleichzeitig ist viermal mehr Speicher mit der GPU gebündelt, was für Partner ebenfalls eine willkommene Nachricht sein dürfte.
Der B200-Grafikprozessor besteht aus zwei Chipsätzen, die aus einer sehr großen Anzahl von jeweils 104 Milliarden Transistoren bestehen und derzeit die größten ihrer Klasse sind. Die beiden Chipsätze des B200-Grafikprozessors werden mit der modernsten und leistungsfähigsten Fertigungstechnologie der 4N-Klasse von TSMC hergestellt, die als 4NP bekannt ist. Der Grafikprozessor besteht aus insgesamt 208 Milliarden Transistoren und einer einzigartigen Verbindung zwischen den beiden Chipsätzen, die eine extrem hohe Datenbandbreite von 10 TB/s ermöglicht. Dank dieser enormen Datenbandbreite ist die Kommunikation zwischen den Chipsätzen schnell genug mit geringer Latenz, d.h. es wird Cache-Kohärenz erreicht, d.h. die GPUs können mit derselben Geschwindigkeit auf den Speicherplatz des jeweils anderen zugreifen, als wäre es ihr eigener, mit einer direkten Verbindung.

Das Speichersubsystem beider Chipsätze ist ein 4096-Bit-Speicher-Subsystem, das mit 96 GB On-Board-Speicher vom Typ HBM3E verbunden ist, der als vier 24-GB-Speicherchip-Sandwiches verfügbar ist, so dass der gesamte B200-Chip insgesamt 192 GB On-Board-Speicher einsetzen kann. Auch an der Speicherbandbreite wurde nicht gespart: Sie beträgt 8 TB/s und ist damit nicht viel geringer als die individuelle Verbindung zwischen den Chipsätzen. Natürlich gibt es auch NVLink-Unterstützung, die es der GPU ermöglicht, sich mit dem Server und einem anderen B200-Chip zu verbinden, mit einer Bandbreite von 1,8 TB/s, was ebenfalls enorm ist.

Darüber hinaus hat das Unternehmen den GB200 Superchip eingeführt, der nun insgesamt zwei GB200-GPUs enthält, so dass insgesamt vier Chipsätze mit insgesamt 384 GB On-Board-Speicher zur Verfügung stehen. Die aus insgesamt 416 Milliarden Transistoren aufgebauten GPUs kommunizieren natürlich über NVLink, und es ist auch ein ARM-basierter Grace-Superchip an Bord, bei dem es sich um den Grace-Hopper-Superchip der vorherigen Generation GH200 handeln könnte, da das Produkt nicht von Nvidias Frontmann gelobt wurde, so dass es sich wahrscheinlich nicht um eine Neuentwicklung handelt. Der Grace-Hopper Superchip ist einem x86-64-Serverprozessor der AMD EPYC- oder Xeon Scalable-Serie vorzuziehen, da NVLink eine höhere Datenbandbreite zwischen den Komponenten bietet und die spezielle Architektur den Chip besser für KI-Workflows geeignet macht.
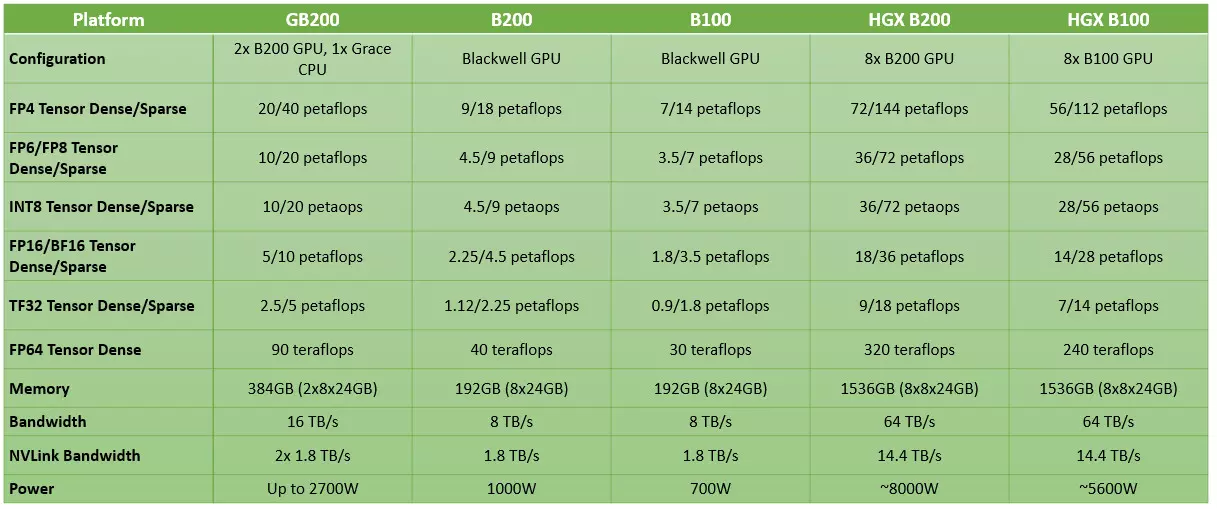
Damit kommen wir zur Leistung der einzelnen B200-GPUs und der GB200-Lösung. Leider hat der Nvidia-Chef nicht verraten, wie genau die einzelnen GPUs aufgebaut sind, so dass die genauen Parameter der SM-Arrays, CUDA-Kerne, Tensor-Kerne und Caches nicht bekannt sind, aber wir können eine enorme Rechenleistung erwarten. Die einzelnen B200-Chips sind Berichten zufolge in der Lage, bei Deduktions-Workflows eine Rechenleistung von 20 PFLOP/s zu erzielen, was 20.000 TFLOP/s entspricht. Beim GB200 könnte dieser Wert bei 40 PFLOP/s liegen, wenn die FP4-Tensor-Rechenleistung genutzt wird. Auch die FP64-Rechenleistung ist mit einem Wert von 90 TFLOP/s beeindruckend, dreimal höher als beim Hopper-basierten GH200.
Natürlich muss darauf hingewiesen werden, dass die Leistung des B200 von 20 PFLOP/s bei Verwendung des FP4-Zahlenformats in Bezug auf die Beschleunigung etwas irreführend ist. Betrachtet man die FP8-Ebene, wo die Leistung halb so hoch ist wie im FP4, beträgt der Leistungsunterschied zwischen dem B200 und dem H100 nicht das Fünffache, sondern das Zweieinhalbfache (10 PFLOP/s gegenüber 4 PFLOP/s).
Neue Entwicklungen von Nvidia werden voraussichtlich noch in diesem Jahr auf den Markt kommen.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}