Im April kündigte Microsoft Phi-3 an, ein offenes, "kleines Sprachmodell", das unabhängig von OpenAI entwickelt wurde und hervorragende Leistung bei geringem Platzbedarf bieten soll. Jetzt hat Microsoft dieses Tool auf den Weg zum multimodalen Betrieb gebracht, indem es in seiner neuen Variante auch die Arbeit mit Bildern ermöglicht.
Phi-3-vision kommt, und es führt die Fähigkeiten des Sprachmodells in eine neue Richtung.
Die Microsoft-Ingenieure haben ein multimodales Tool entwickelt, das noch recht klein ist, so dass es auf lokal laufenden Smartphones eingesetzt werden kann. Neben Textinhalten wird Phi-3-vision auch in der Lage sein, Bilder zu "sehen", was es für die tägliche Arbeit noch nützlicher macht.
Das neue Sprachmodell ist bereits in einer Preview-Version von Microsoft verfügbar. Phi-3-vision arbeitet mit 4,2 Milliarden Parametern, was bedeutet, dass es selbst in der Phi-3-Modellfamilie zu den kleineren Lösungen hinzukommt. Aber das Unternehmen verspricht, dass es sich dennoch als ein hervorragender Kollaborateur mit viel Potenzial erweisen wird. Das neue SLM-System (Small Language Model) wird in der Lage sein, Fotos, gescannte Dokumente und reinen Text zu verarbeiten.

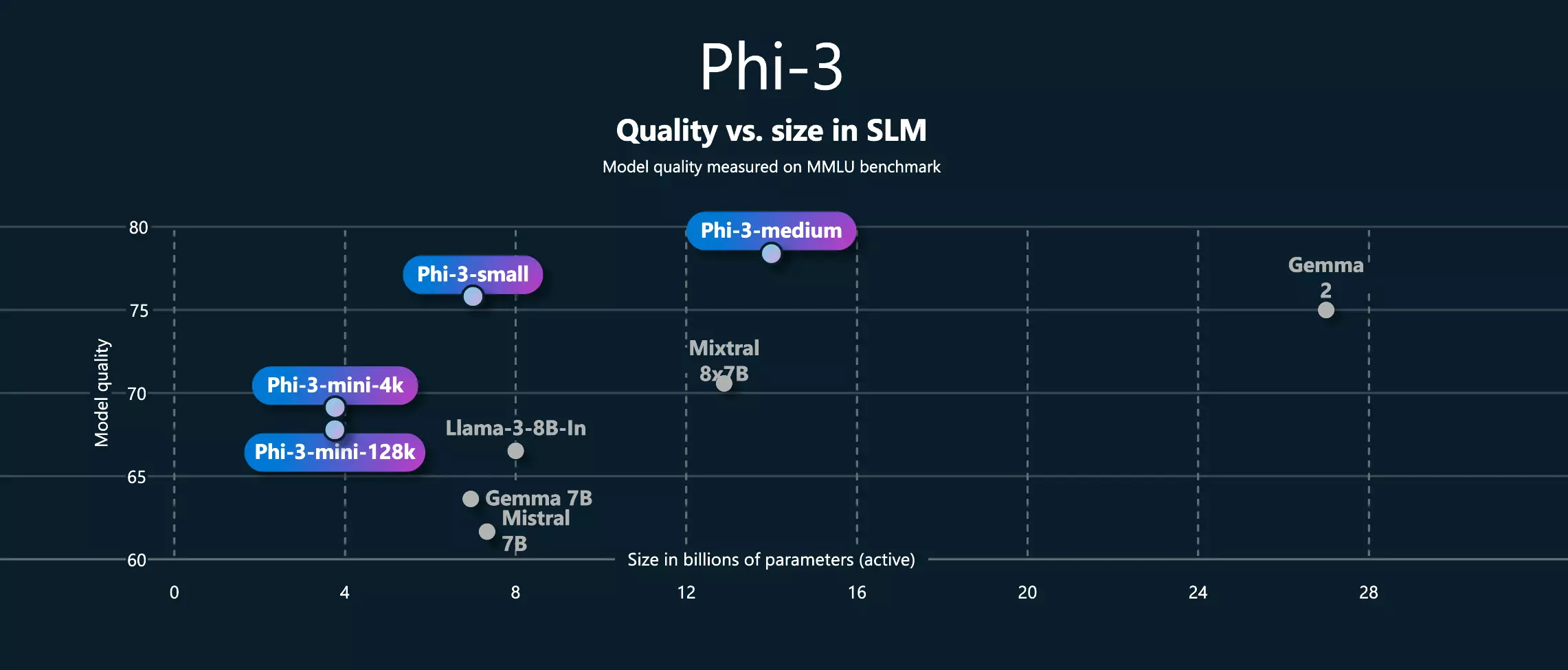
Damit steigt die Zahl der Phi-3-Systeme auf vier. Der Phi-3-mini, der im April auf den Markt kam, konnte sich in verschiedenen Tests mit nur 3,8 Milliarden Parametern mit dem Llama 3 mit 8 Milliarden Parametern, dem Mistral mit 7 Milliarden Parametern und dem Gemma mit 7 Milliarden Parametern messen. Das Unternehmen ist stolz darauf, dass alle Konfigurationen des Phi-3 unter den Geräten derselben Größe hervorstechen.
Der Phi-3-smll verfügt nun über 7 Milliarden Parameter, und obwohl er auch mit weniger Rechenleistung sehr gut eingesetzt werden kann, leistet er bereits hervorragende Arbeit und kann sogar mit dem GPT-3.5 konkurrieren. Der Phi-3-medium ist derzeit die seriöseste Konfiguration, aber auch dieser hat nur 14B Parameter. Microsoft entwickelt den Phi-3-Medium noch weiter, aber erste Tests deuten darauf hin, dass er mit Modellen mit mehr als 50B Parametern konkurrieren kann. Diese Modelle sind klein, leicht und können eine Menge, und der Phi-3-vision unterstützt bereits mehrere Datenformate.
Es sollte hinzugefügt werden, dass die generative KI in diesem Fall immer noch an der Texterstellung festhält, nur die Eingabedaten können Bilder sein, Phi-3-vision kann keine Bilder erstellen. Da die Phi-3-Modelle sehr effizient sind, können sie zu deutlich geringeren Kosten betrieben und genutzt werden, da sie keine extreme Rechenleistung wie GPT-4 oder Gemini 1.5 benötigen.
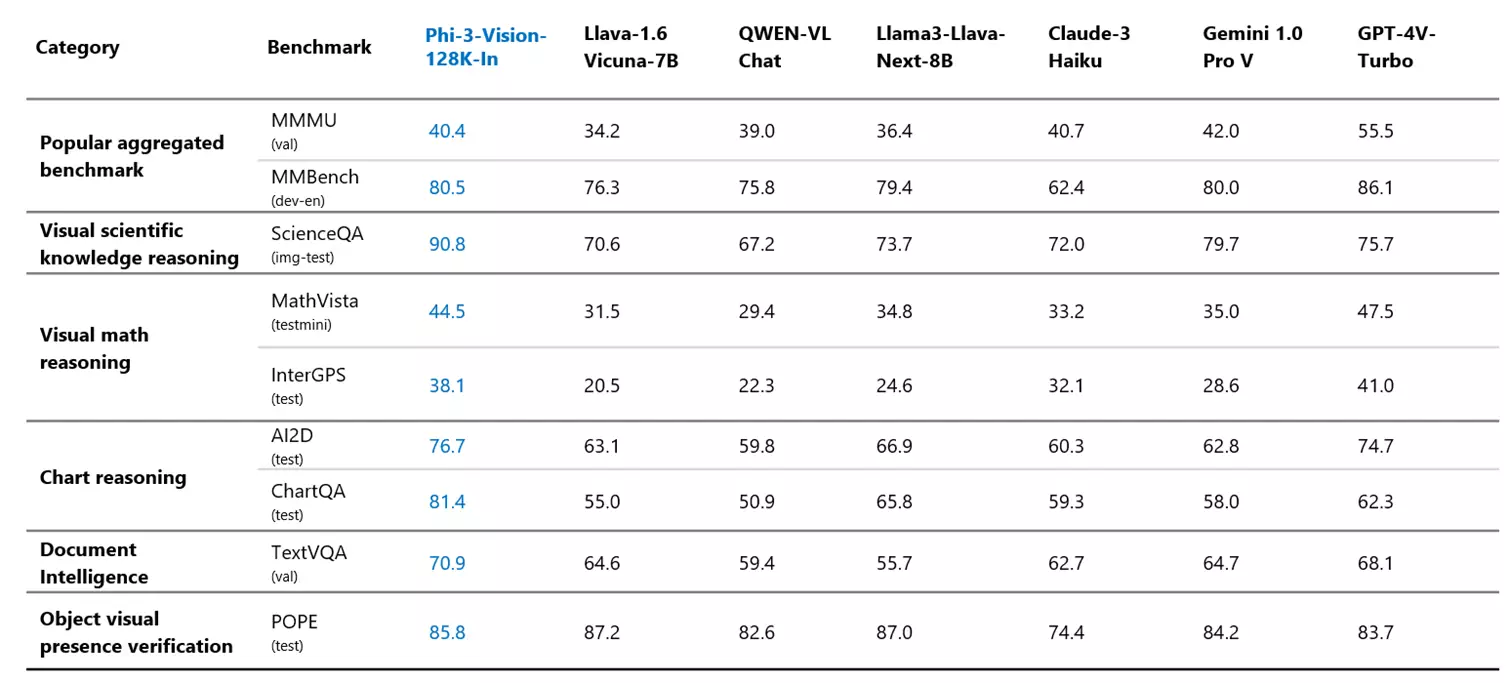
Nach den von Redmond veröffentlichten Testergebnissen kann der Phi-3-vision dem multimodalen Modell Google Gemini 1.0 Pro V getrost Paroli bieten und je nach Situation und Herausforderung sogar besser abschneiden als der GPT-4V Turbo. Und das neue Phi-SLM-System schneidet in praktisch allen Bereichen besser ab als das von Meta entwickelte Llama 3 Llama Next 8B.
Microsoft stellt natürlich auch ein Cloud-Backend für die Phi-3-Sprachmodelle zur Verfügung, das auf Azure zurückgreifen kann. Hugging Face bietet auch die Möglichkeit, diese zu testen.
