
Google entwickelt seine verschiedenen Sprachmodelle und die darauf basierenden generativen Dienste für künstliche Intelligenz in rasantem Tempo. Das Unternehmen ist bestrebt, in diesem Bereich eine Vorreiterrolle einzunehmen, aber OpenAI und Microsoft erweisen sich gemeinsam als ernstzunehmende Konkurrenten; deshalb hat Google über alle aktuellen Entwicklungen berichtet, um so viel wie möglich in den Nachrichten zu sein.
Das Unternehmen hat gerade auf der Konferenz Cloud Next 2024 bekannt gegeben, dass Gemini 1.5 Pro das Stadium erreicht hat, in dem es von der Öffentlichkeit getestet werden kann. Vertex AI ist eine Testumgebung, um zu sehen, was das Modell der neuen Generation leisten kann, das jetzt eine neue Architektur (Mixture of Experts) verwendet, um es effizienter und genauer zu machen und um es mit bis zu 1 Million Token von Kontextfenstern stabil zu machen, gegenüber 128.000 Token, die die Obergrenze waren.

Google kündigte Gemini erst im Dezember an und begann dann im Februar, über Gemini 1.5 zu sprechen. Die mittlere Stufe davon ist Gemini 1.5 Pro, das jetzt für ein kleineres Publikum verfügbar ist. Gemini 1.5 Pro soll bereits so leistungsfähig sein, dass es das Modell Gemini 1.0 Ultra übertrifft, das das größte LLM-System ist, das derzeit von dem Suchgiganten angeboten wird, und es wird sogar eine Ultra-Version von Gemini 1.5 geben. Gemini 1.0 Ultra ist derzeit über den abonnementbasierten Dienst Gemini Advanced erhältlich.
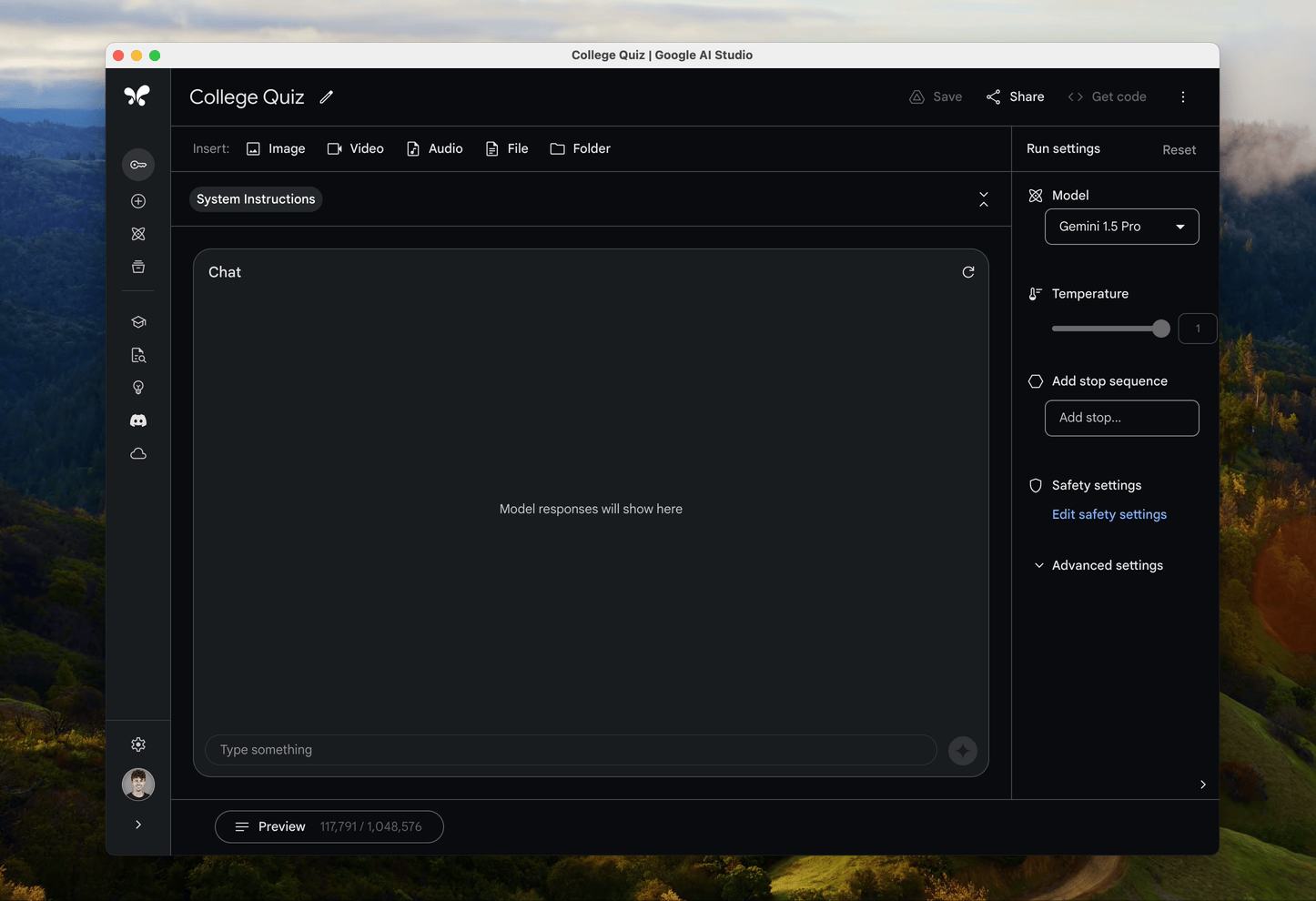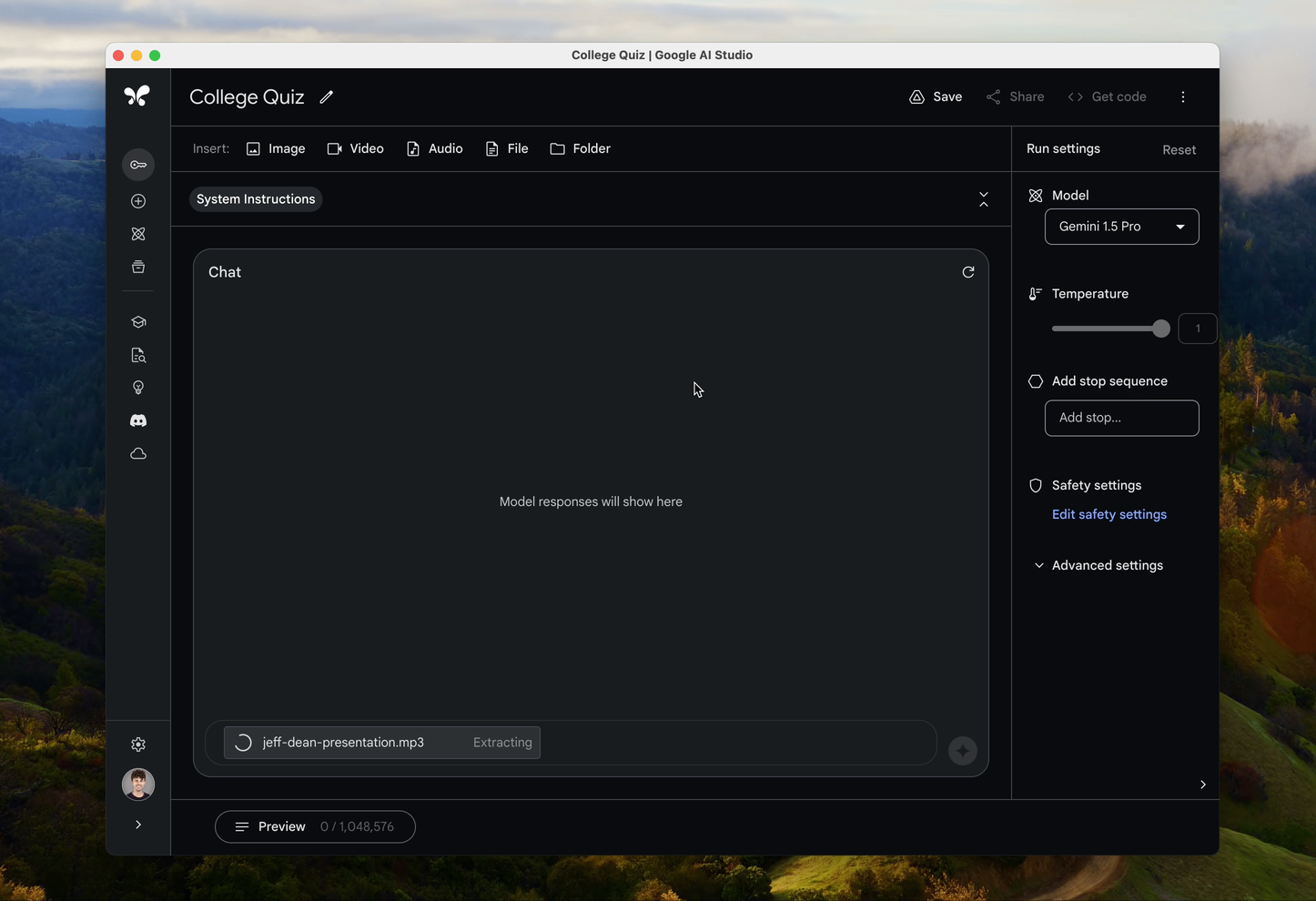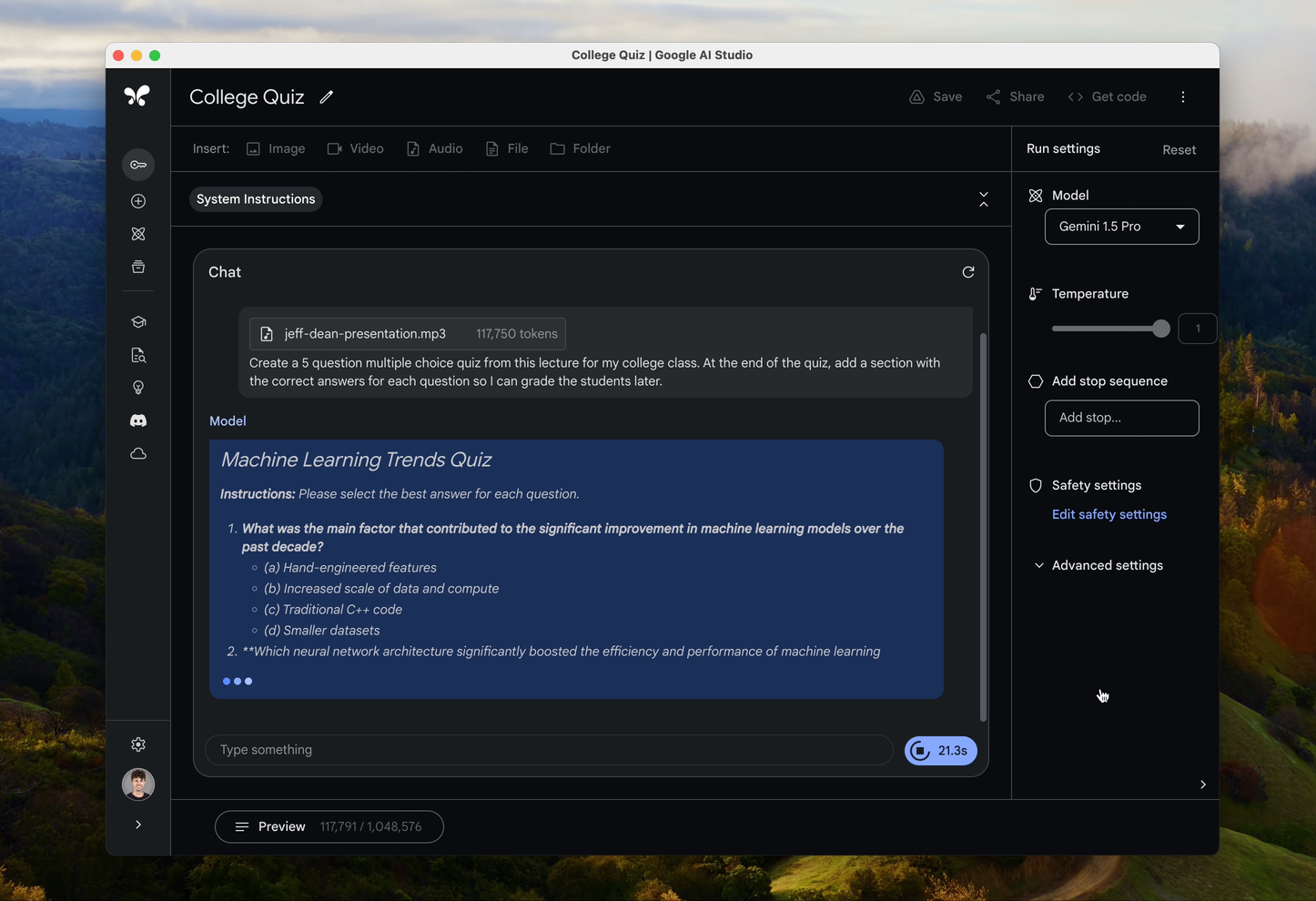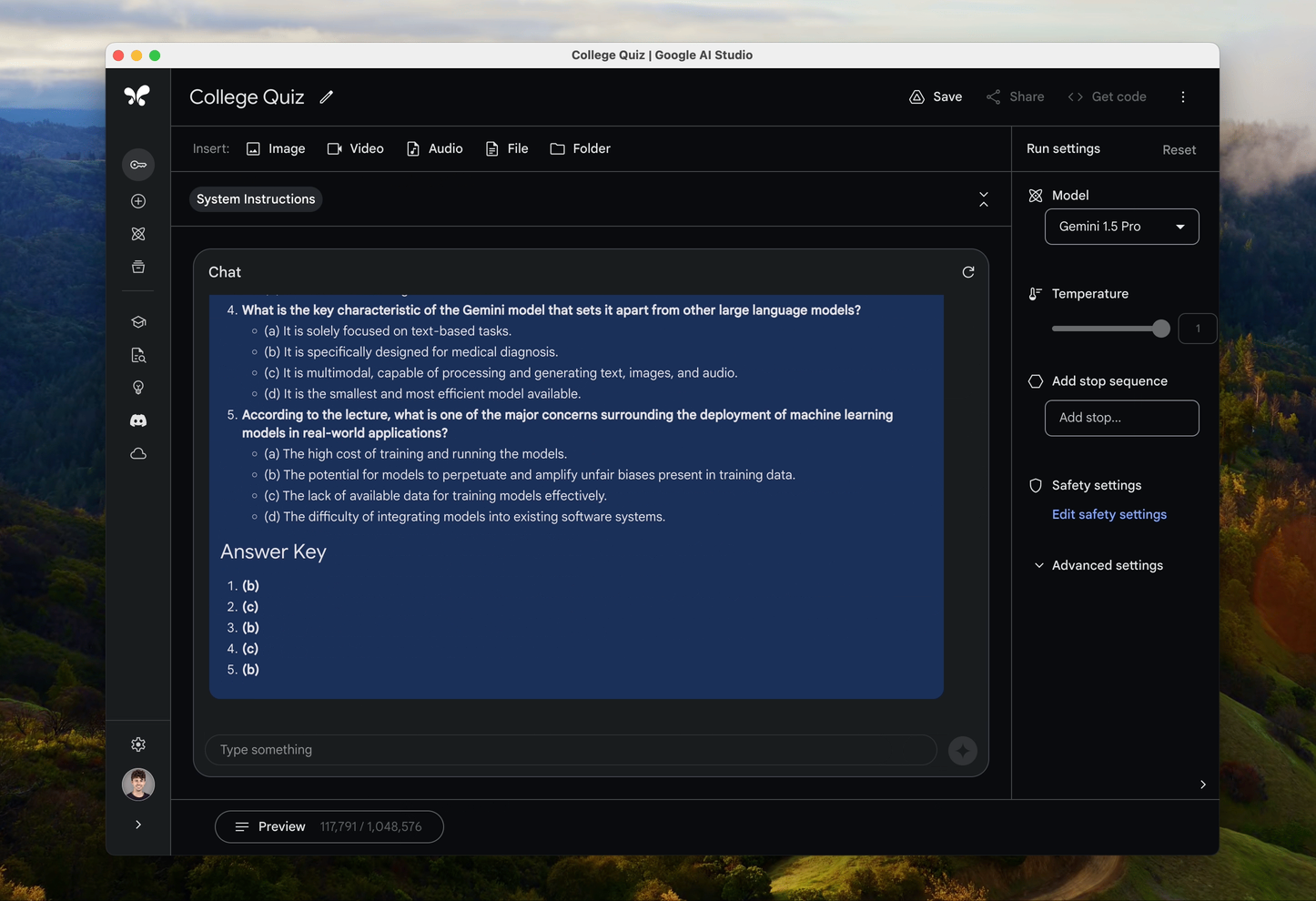
Wir haben bereits von der Fähigkeit von Gemini 1.5 Pro erfahren, neben Text auch Bilder und Videos zu verarbeiten, und nun sind auch Audio-Inhalte in diese Reihe aufgenommen worden. Das Unternehmen hat angekündigt, dass es nun in der Lage sein wird, sein umfangreiches Sprachmodell zu nutzen, um verschiedene Audioaufnahmen zu analysieren und deren Inhalt zu verstehen. Es wird auch in der Lage sein, verschiedene Audiomaterialien zu vergleichen, und natürlich wird es in diesem Bereich Unterstützung für mehrere Sprachen geben.
Die oben erwähnten 1 Million Token-Stimmproben entsprechen etwa 11 Stunden ununterbrochener Aufzeichnung. Mit der generativen KI-Technologie, die das Gemini 1.5 Pro-Sprachmodell verwendet, können Sie also fast einen halben Tag ununterbrochener Konversation verarbeiten und Fragen beantworten, eine Zusammenfassung verfassen und so weiter. Diese Innovation macht es zum Beispiel einfach, Videos mit Untertiteln zu versehen, Liedtexte für Musikclips bereitzustellen und so weiter.
Es wäre nicht verwunderlich, wenn Google in Zukunft das neueste Gemini-Modell bei YouTube einsetzen würde, denn die Beziehung von YouTube zu KI beruht auf der Tatsache, dass das Unternehmen bereits ein Tool für die Spracherkennung und Untertitelung eingesetzt hat, das sich noch in der Entwicklung befand. Das Unternehmen gibt in der Regel nicht viel Einblick in diesen Bereich, so dass es nicht klar ist, wie die Situation an dieser Front ist.
Was das Unternehmen auf der Cloud Next-Veranstaltung sagte, war, dass Gemini 1.5 Pro seinen Weg in immer mehr Dienste finden wird und dass es zum Beispiel in Code Assist, seinem programmierunterstützenden generativen KI-Tool, integriert werden soll, um die Leistung in allen Aspekten zu verbessern. In der Programmierung soll es mit der Veröffentlichung des neuen Modells eine enorme Verbesserung geben, und das Unternehmen will dies auch sofort nutzen, um das Interesse der Nutzer zu wecken.

Google hat auch angedeutet, dass seine Text-zu-Bild-KI-Lösung, Imagen 2 genannt, die Dinge auf die nächste Stufe heben wird. Sie wird bereits über Funktionen wie internes Auffüllen und Verbreiterung der Leinwand verfügen, so dass zum Beispiel Elemente aus Bildern entfernt und durch völlig unauffällige Elemente ersetzt werden können. Ähnliche Funktionen wurden in letzter Zeit bereits den meisten Bildgeneratoren hinzugefügt, so dass es nicht verwunderlich ist, dass auch Google sich mit Verbesserungen in diese Richtung bewegt. Darüber hinaus wird Google auch damit beginnen, Bilder mit Wasserzeichen zu versehen, die die neue SynthID verwenden.
