
Die diesjährige Google I/O steht ganz im Zeichen der künstlichen Intelligenz. Die Eröffnungsveranstaltung dauerte 2 Stunden, aber das Unternehmen könnte wahrscheinlich noch stundenlang über die LLM- und KI-Entwicklungen berichten, die es auf Lager hat. Es wird dies in den nächsten Tagen mit weiteren, kleineren Präsentationen tun, da die Google I/O tagelang andauert.
Wir haben bereits berichtet , dass das Unternehmen mehrere wichtige Ankündigungen zu Gemini gemacht hat. Gemini 1.5 Pro wird in Zukunft mit einem größeren Kontextfenster arbeiten können und bis zu 2 Millionen Token statt bisher 1 Million verarbeiten können. Damit wird es auch in der Lage sein, sehr lange Videos zu verarbeiten. Außerdem wurde das Modell Gemini 1.5 Flash eingeführt, das eine kleine, leichte und preisgünstige Variante der Produktreihe sein wird, die jedoch in Situationen, in denen sie häufig benötigt wird, hervorragende Leistungen erbringen wird.

Das generative KI- und LLM-Tool Gemini wird auch in verschiedenen Formen innerhalb des Android-Frameworks zur Verfügung stehen, worüber wir in einer separaten Meldung berichtet haben. Aber auch andere Sprachmodelle wurden auf der Google I/O diskutiert. Das Unternehmen sprach über die Richtung, die Gemma einschlägt. Wir haben zum ersten Mal im Februar davon gehört , das der Suchmaschinengigant kurz nach der Enthüllung von Gemini 1.5 angekündigt hatte.
Gemma ist ein Sprachmodell, das als Open Source bezeichnet wird, aber es ist nicht so sehr Open Source. Es kann von Google-Partnern kostenlos genutzt werden, aber es steht außer Frage, dass es in jeder Hinsicht öffentlich und transparent ist, auch was die Daten angeht, mit denen es trainiert wurde. Im Februar wurden eine Version mit 2 Milliarden und eine Version mit 7 Milliarden Parametern veröffentlicht, gefolgt von den Optionspaaren CodeGemma und RecurrentGemma, und jetzt sind zwei neue Modelle hinzugekommen.

Es wird nun ein visuelles Gemma-Modell in der Reihe geben, das PaliGemma heißen wird. Dies ist das erste offene visuelle Sprachmodell von Google, das für die Erkennung von Bildunterschriften mit herausragender Effizienz optimiert ist. Es eignet sich hervorragend für die Verwaltung von Produktetiketten, Dokumente und mehr. PaliGemma ist ein vortrainiertes Modell, bei dem Bilder und Videos das "Lernmaterial" für die künstliche Intelligenz darstellen.

PaliGemma wird sich auf einer völlig anderen Ebene bewegen als einfache Bilderkennungslösungen, es wird in der Lage sein, nicht nur Fotos, sondern auch sehr spezifische Bilder zu analysieren, zum Beispiel im Bereich der Medizin, aber auch Satellitenbilder und Luftaufnahmen. Es kann jeden visuellen Bereich bearbeiten und zeichnet sich gleichzeitig durch eine hervorragende Texterkennung aus.
Eine weitere Neuheit ist das Modell Gemma 2, das, wie der Name schon sagt, die zweite Generation von Gemma darstellt, auch wenn die erste Ausgabe noch sehr jung ist. Die vorherigen Gemma LLM-Geräte hatten weniger als 10 Milliarden Parameter, aber das ist bei Gemma 2 mit 27 Milliarden Parametern ganz anders.

Google wollte es leichtgewichtig halten, weshalb es auf einem sehr hohen Niveau optimiert wurde. Insbesondere wurde mit Nvidia zusammengearbeitet, um die Software so zu optimieren, dass sie auf den Grafikprozessoren der nächsten Generation gut funktioniert. Auch auf den Google-eigenen TPU-Prozessoren wird es eine hervorragende Effizienz erreichen. Und das Versprechen ist, dass er es mit Modellen aufnehmen kann, die bis zu doppelt so groß sind wie das Arbeitstier.
Wenn alles nach den Plänen von Google läuft, könnte Gemma 2 im Juni erhältlich sein. Wie das Unternehmen auf der Entwicklerkonferenz mitteilte, wird es sich voraussichtlich großer Beliebtheit erfreuen: Die ersten beiden Gemma-Sprachmodelle wurden seit ihrer Veröffentlichung millionenfach heruntergeladen. Und auch die neueren Ergänzungen der Produktpalette stoßen auf großes Interesse.

Eine weitere aufregende Entwicklung im Bereich der künstlichen Intelligenz von Google ist Veo, das brandneue KI-Tool des Unternehmens zur Videogenerierung. Es wird als Teil von VideoFX verfügbar sein und in der Lage sein, bewegte Bilder auf der Grundlage von Befehlen zu erzeugen.
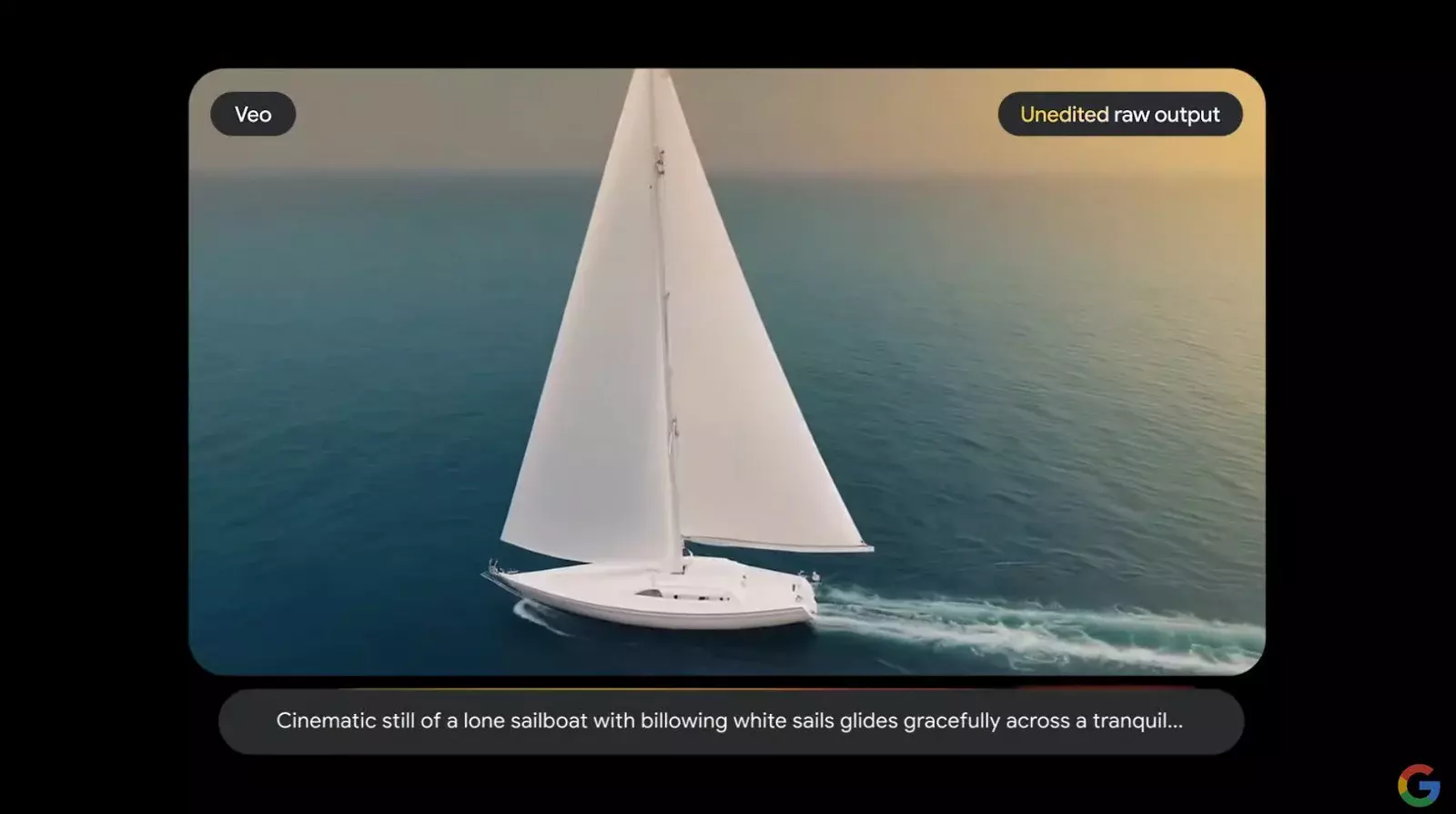
Es gibt bereits viele verschiedene videogenerative KI-Lösungen, aber Google verspricht, dass Veo eine herausragende Qualität liefern wird, und dies wird durch die Tatsache angedeutet, dass es in der Lage sein wird, Filmmaterial in 1080p-Auflösung auf Befehl des Benutzers zu produzieren. Auf der Google I/O zeigte das Unternehmen mehrere Rohdemos, um zu zeigen, wie gut Veo funktioniert.

Das Unternehmen sprach auch über sein LearnLM-Sprachmodell, das sich bei der Lösung von Bildungsaufgaben auszeichnen wird. Seine Aufgabe wird es sein, nicht nur Hausaufgaben zu lösen, sondern sie auch in einer Form zu präsentieren, die Schüler verstehen können. Diese Entwicklung wurde bereits in den Android-Neuheiten erwähnt, da sie die erste sein wird, die in Android eingeführt wird und Schülern beim Lernen auf Mobiltelefonen helfen soll. LearnLM wird auch in Google Classroom verfügbar sein und Lehrern bei der Unterrichtsplanung helfen.

Auf der Google I/O wurde auch erwähnt, dass das Unternehmen ständig daran arbeitet, sicherzustellen, dass der Einsatz von künstlicher Intelligenz unter allen Umständen verantwortungsvoll und ethisch vertretbar ist. Google ist nach eigenen Angaben führend bei der Erforschung von Schwachstellen und Missbrauch und setzt in diesem Bereich bereits KI ein. KI-Helfer und Menschen arbeiten zusammen, um die Gefahr des Missbrauchs Ihrer Tools in Zukunft zu verringern.
Zuvor hatte Google SynthID eingeführt, ein Wasserzeichen, das mit generativer KI erstellte Inhalte leicht erkennbar und identifizierbar macht. Es diente zunächst für Fotos, dringt nun aber in neue Gewässer vor. SynthID wird nun in der Lage sein, eine Kennung in Texte und generierte Videos einzubetten. Interessant ist, wie das Wasserzeichen im Text erscheinen wird, aber Google arbeitet bereits daran. Es wurde auch bekannt, dass sie bei der Entwicklung mit der C2PA-Organisation zusammenarbeiten.

Die auf der Google I/O angekündigten Neuerungen werden nach und nach zur Verfügung gestellt.
