Für die verschiedenen Arbeitsabläufe im Zusammenhang mit künstlicher Intelligenz wird immer leistungsfähigere Hardware benötigt, da große Sprachmodelle immer komplexer werden, was neben der Rechenleistung auch einen erheblichen Anstieg des Stromverbrauchs zur Folge hat, so dass ein energieeffizienter Betrieb immer wichtiger wird.
Die KI-Entwicklung von Positron ist nicht nur in Bezug auf die Leistung mit den marktführenden H200-KI-Beschleunigern von Nvidia konkurrenzfähig, sondern auch in Bezug auf die Energieeffizienz: Sie bietet nicht nur eine höhere Leistung als die Produkte von Nvidia, sondern erledigt ihre Aufgaben auch mit etwas mehr als einem Drittel des Stromverbrauchs, was dem Nvidia-Team das Fürchten lehrt.

Natürlich muss darauf hingewiesen werden, dass Positrons Beschleuniger der AI-Atlas-Serie ein spezieller ASIC ist, der bei weitem nicht so vielseitig ist wie beispielsweise ein Nvidia H200: Er ist nur für einen einzigen AI-Aufgabentyp optimiert, die AI-Inferenz, bei der er viel effizienter arbeiten kann als Nvidias Produkt. Positron AI ist ein relativ junges Unternehmen, das 2023 gegründet wurde und sich auf die Entwicklung und Herstellung energieeffizienter und leistungsstarker Lösungen für einen bestimmten Bereich, die Welt der KI-Inferenz, spezialisiert hat. Dementsprechend können diese Beschleuniger nicht für allgemeines Computing, Training oder andere Workflows verwendet werden, aber für die Ableitung sind sie selbst Nvidias H200-Lösungen, die auf der Hopper-Architektur basieren, weit voraus.
Die Atlas genannte Lösung besteht im Wesentlichen aus acht Archer-Beschleunigerkarten, die bei der Ausführung von Aufgaben eng zusammenarbeiten. Dieses System wurde mit dem DGX-Server von Nvidia verglichen, ebenfalls ein Server mit acht Pfaden und H200-KI-Beschleunigern. Die internen Tests - die, wie bei dieser Art von Messungen üblich, mit einem gesunden Maß an Misstrauen behandelt werden sollten - zeigten, dass Atlas im BF16-Modus unter Llama 3.1 8B 280 Token pro Sekunde und Benutzer generierte, während Nvidias H200-basierter DGX-Server unter den gleichen Bedingungen nur 180 Token erzeugen konnte. Dies ist ein signifikanter Unterschied in der Leistung, aber der Unterschied im Stromverbrauch ist noch dramatischer: Während der Atlas 2000 W für den Betrieb benötigte, verbrauchte der Nvidia DGX-Server 5900 W-ps.
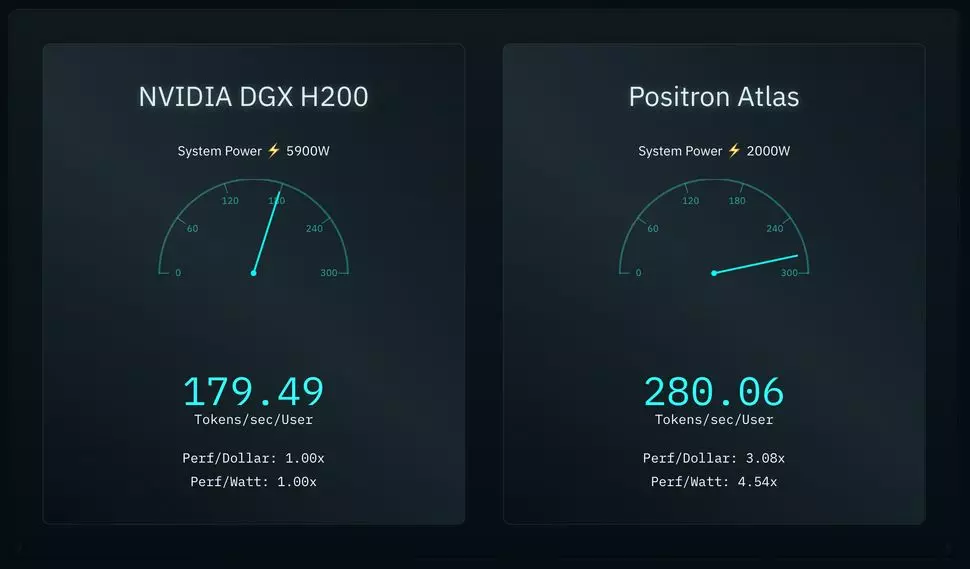
Dies zeigt, dass Atlas nicht nur schneller ist als sein Konkurrent, sondern auch fast dreimal energieeffizienter, was sehr wichtig ist, und dass er auch im Hinblick auf das Preis-Leistungs-Verhältnis viel besser ist als die Lösung von Nvidia. Natürlich müssen diese Behauptungen von unabhängigen Prüfern verifiziert werden, bevor sie als Tatsache akzeptiert werden können.
Der Atlas-Beschleuniger kann als ein fast ausschließlich amerikanisches Produkt betrachtet werden, da ein Teil seiner Entwicklung und Produktion in den Vereinigten Staaten von Amerika stattfindet. Der spezielle ASIC wird in der TSMC-Fabrik Fab 21 in Arizona hergestellt, wo N4- und N5-Fertigungstechnologien zum Einsatz kommen. Der Chip verfügt außerdem über 32 GB HBM-Speicher und verwendet eine fortschrittliche Verkapselungstechnologie, so dass er wahrscheinlich in Taiwan montiert wird.
Positiv zu vermerken ist, dass der Atlas-Server und die Archer-KI-Beschleuniger mit den meisten weit verbreiteten KI-Beschleunigern wie den Lösungen von Hugging Face vollständig kompatibel sind und auch Ableitungsanfragen über einen OpenAI-API-kompatiblen Endpunkt entgegennehmen können, so dass sie relativ einfach und ohne größere Änderungen in bestehende Arbeitsabläufe integriert werden können.

Im Hintergrund arbeitet Positron bereits an der nächsten Hardware-Generation, die auf den Asimov-KI-Beschleunigern basiert und Titan genannt wird. Es wird ebenfalls ein Acht-Wege-System sein, d. h. es wird acht Beschleunigerkarten enthalten, aber seine Konkurrenten werden nicht mehr Hopper oder Blackwell sein, sondern Nvidia-Produkte, die auf der Vera-Rubin-Architektur basieren. Titan kann nun bis zu 2 TB Speicher pro ASIC bieten, und die Kommunikation mit Rack-Systemen kann über ein Netzwerk mit einer Datenbandbreite von 16 TB/s erfolgen.
Die neuen Acht-Wege-Systeme können LLMs mit bis zu 16 Billionen Parametern ausführen, und das System ermöglicht auch die gleichzeitige Ausführung mehrerer Modelle, wodurch die Beschränkung auf ein einziges Modell/GPU aufgehoben wird. Das Unternehmen verspricht, dass der Titan in Bezug auf Leistung und Preis/Leistung fünfmal besser sein wird als Nvidias Ruby-basierter DGX-Server, was sich sehr gut anhört, wenn sich diese Behauptung in der Realität bewahrheitet. Der Titan wird voraussichtlich im Jahr 2026 auf den Markt kommen und mit 175.000 US-Dollar genauso viel kosten wie der derzeit erhältliche Atlas.
