
Neben den Spitzenreitern im KI-Rennen entwickeln bereits viele andere ihre eigenen Modelle, und auch Xiaomi kommt in diesem Bereich immer besser in Fahrt. Das neueste offene Modell MiMo-V2.5 des Unternehmens ist bereits auf einem sehr ähnlichen Niveau wie das vor einigen Tagen angekündigte DeepSeek-V4 ..
MiMo-V2.5 ist ein Modell mit einer Sparse Mixture-of-Experts (MoE)-Architektur, was der Hauptgrund dafür ist, dass es extrem effizient sein wird. Es verfügt über insgesamt 310 Milliarden Parameter, von denen bis zu 15 Milliarden aktiv sein können. Eine Pro-Variante dieses Modells ist ebenfalls verfügbar, die sich durch eine höhere Leistung auszeichnet und 1,02 Billionen Parameter in MoE-Architektur und 42 Milliarden aktive Parameter aufweist.

Xiaomi wird seinen Partnern die Möglichkeit bieten, die Modelle fein abzustimmen und sie auf der Grundlage spezifischer Daten neu zu trainieren, um in verschiedenen Bereichen bessere Leistungen zu erzielen. Der MiMo-V2.5-Pro ist nun auf die Lösung explizit komplexer Agentenaufgaben ausgerichtet, kann mit großen Datenmengen umgehen und auch Programmieraufgaben effizient durchführen. Beide neuen Funktionen arbeiten mit einem Kontextfenster von 1 Million Token.
Die Entwickler haben MiMo-V2.5 mit dem Fokus auf nativen multimodalen Betrieb erstellt. Das bedeutet, dass neben Textanweisungen auch Bilder, Video und Audio nahtlos verarbeitet werden können. Außerdem wird es Ihnen ermöglichen, effektiver zu argumentieren, genauer zu reagieren und bei der Ausführung von Agentenaufgaben flexibel zu sein. Das Unternehmen betonte, dass eine riesige Datenmenge, nämlich 48 Billionen Token, zum Trainieren des Basismodells verwendet wurde.
MiMo-V2.5 ist das effizienteste Modell zur Lösung von Agentenaufgaben, das derzeit auf dem Markt ist, so Xiaomi.
Das neue Gerät ist eine hervorragende Lösung für den Betrieb von OpenClaw, NanoClaw und ähnlichen Diensten, was angesichts ihrer unglaublichen Popularität ein gutes Zeichen ist. Im ClawEval-Test haben nur die Claude-Modelle das MiMo-V2.5 geschlagen, aber sie sind in Bezug auf die Effizienz nicht konkurrenzfähig.
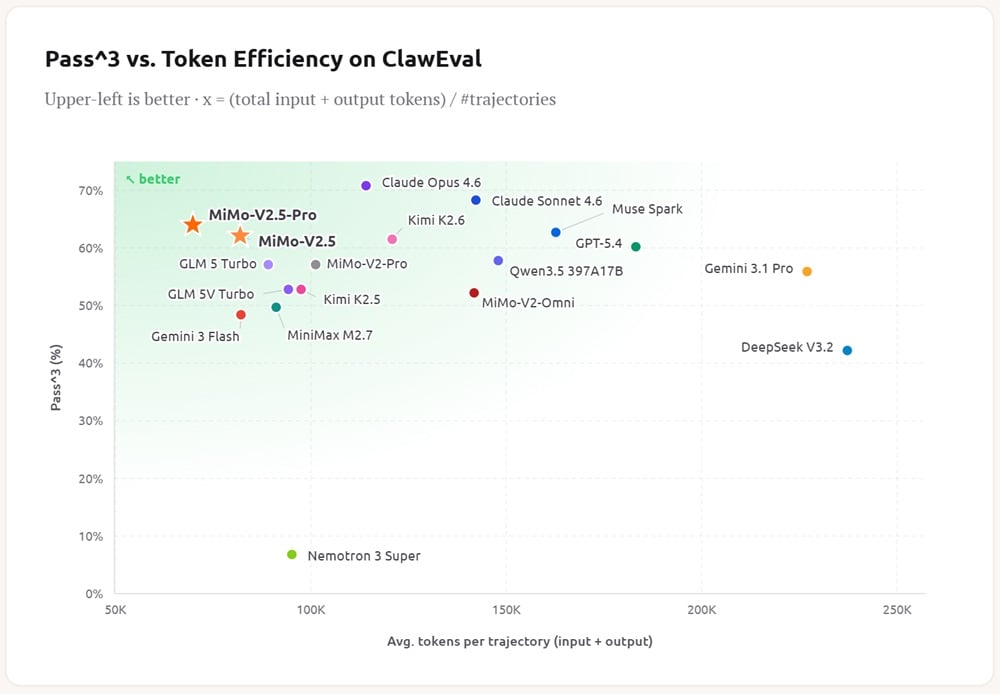
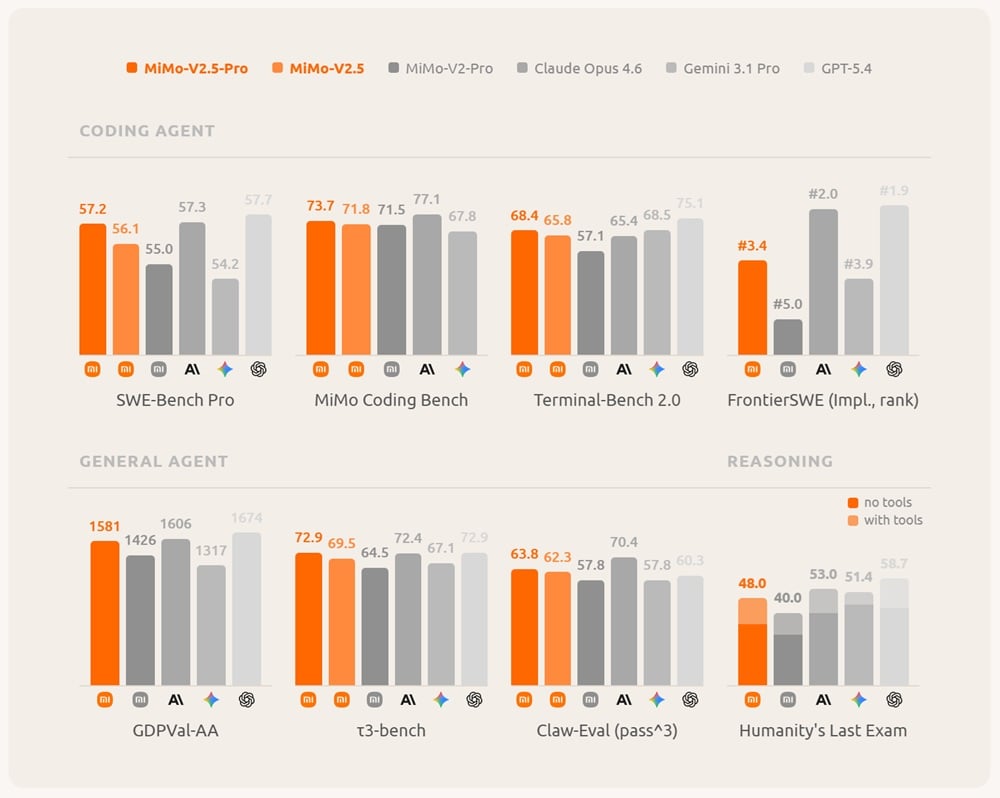
In seinen eigenen Messungen hat Xiaomi das MiMo-V2.5 trickreich mit den früheren Opus- und GPT-Modellen verglichen, aber es schneidet im Vergleich zu den neuesten Geräten nicht allzu schlecht ab. Das MiMo-V2.5-Pro erreicht 57,2% im SWE-Bench Pro, während das GPT-5.5 58,6% und das Claude Opus 4.7 64,3% erreicht. Und unter Humanity's Last Exam, ohne "Hilfe", erreicht es 34% gegenüber 43,1% des GPT-5.5 Pro. Xiaomi liegt etwa 1,5 Generationen zurück, aber man darf nicht vergessen, dass es mit viel weniger Ressourcen auskommt als seine oben genannten Konkurrenten.
Der DeepSeek hat sich bereits durch seine kosteneffiziente Arbeitsweise ins öffentliche Bewusstsein geschlichen, da er zu einem Bruchteil des Preises eine ähnliche Leistung wie seine westlichen Konkurrenten erbringt. Nun, Xiaomi verfolgt einen ähnlichen Ansatz bei den Sprachmodellen, und als Ergebnis ist MiMo-V2.5 sogar noch kosteneffektiver als DeepSeek-V4. MiMo-V2.5-Pro kann 1 Million Token für nur $1 verarbeiten und kostet $3, um die gleiche Menge an Inhalten zu generieren. Mit MiMo-V2.5 betragen die Kosten für die Verarbeitung und Erzeugung von 1 Million Token nur 0,4 $ bzw. 2 $.
Xiaomi arbeitet auch an dem Modell MiMo-V2.5-Flash, das voraussichtlich die billigste Lösung unter den populäreren Sprachmodellen sein wird und nur etwa halb so viel kostet wie das derzeit billigste Modell Grok 4.1 Flash.
Die MiMo-V2.5-Modelle sind "vollständig" quelloffene Lösungen und stehen der Allgemeinheit zur Verfügung, auch für die kommerzielle Nutzung. Xiaomi gewährt eine Freiheit, die nicht viele andere in diesem Bereich bieten, und verlangt von seinen Partnern nicht einmal, dass sie die mit benutzerdefinierten Daten feinabgestimmten Modelle nachzertifizieren.
