
Im Mai kündigte OpenAI das Modell GPT-4o an, das auf dem GPT-4 basiert, aber in vielerlei Hinsicht weit über dieses hinausgeht. Je neuer das Modell, desto besser, da sie ständig von den Nutzern verbessert werden, aber so einfach ist diese Geschichte nicht. Mit dem GPT-4o bringt OpenAI nun eine Option auf den Markt, die bisher nur bei älteren Modellen verfügbar war.
Es ist nun möglich, eine Feinabstimmung des neuesten großen Sprachmodells vorzunehmen. In vielen Fällen wird dies weitere Verbesserungen in der Funktionalität und Genauigkeit des Dienstes ermöglichen.
Eine wichtige Neuerung von OpenAI bestand in der Vergangenheit darin, Entwicklern die Möglichkeit zu geben, GPT-Modelle für ihre eigenen Zwecke zu nutzen, indem sie vollständig benutzerdefinierte Datenpakete für das Training verwenden. Dadurch wird die Wahrscheinlichkeit, dass die künstliche Intelligenz halluziniert, erheblich verringert. Falsche Antworten können schwerwiegende Probleme verursachen, vor allem wenn die Genauigkeit entscheidend ist. Natürlich kann die Antwort der KI überprüft werden, aber in manchen Fällen ist das zu umständlich.

Dank dieser neuen Funktion können die Partner noch mehr aus dem GPT-4o-Modell herausholen, und es kann nun auch dort eingesetzt werden, wo es bisher aufgrund fehlender Feinabstimmung nicht anwendbar war. OpenAI wird auch eine größere Freiheit bei der Konfiguration der Arbeitsweise des Modells bieten, so dass es noch besser auf die individuellen Bedürfnisse zugeschnitten werden kann. Vor allem bei technischen Aufgabenstellungen wird die Möglichkeit, GPT-4o mit Daten-Trainingsmaterial zu versorgen, von großem Nutzen sein. Kleinere Datenmengen können die Antwort der generativen KI sogar deutlich verbessern.
OpenAI arbeitet kontinuierlich an seinen Sprachmodellen und versucht, diese in verschiedenen Aspekten regelmäßig zu verbessern. Durch die Möglichkeit der Feinabstimmung wird Entwicklern die Möglichkeit gegeben, das LLM-System für ihre eigenen Zwecke weiter zu verfeinern.
Eine der großen Neuerungen von GPT-4o im Vergleich zu GPT-4 ist, dass es deutlich billiger in der Anwendung, aber immer noch recht teuer in der Ausbildung ist. Nicht nur die Verarbeitung der Daten kostet viel Geld, sondern es müssen auch noch riesige Datenmengen eingegeben werden, wenn auch nicht so viele wie beim ursprünglichen Trainingsverfahren. 25 Dollar kostet die Verarbeitung von einer Million Token während des Trainings, wenn man sich für eine Feinabstimmung entscheidet. Danach kostet die Eingabe von 1 Million Token im normalen Gebrauch nur noch 3,75 $, aber 15 $ pro 1 Million Token in der Ausgabe.
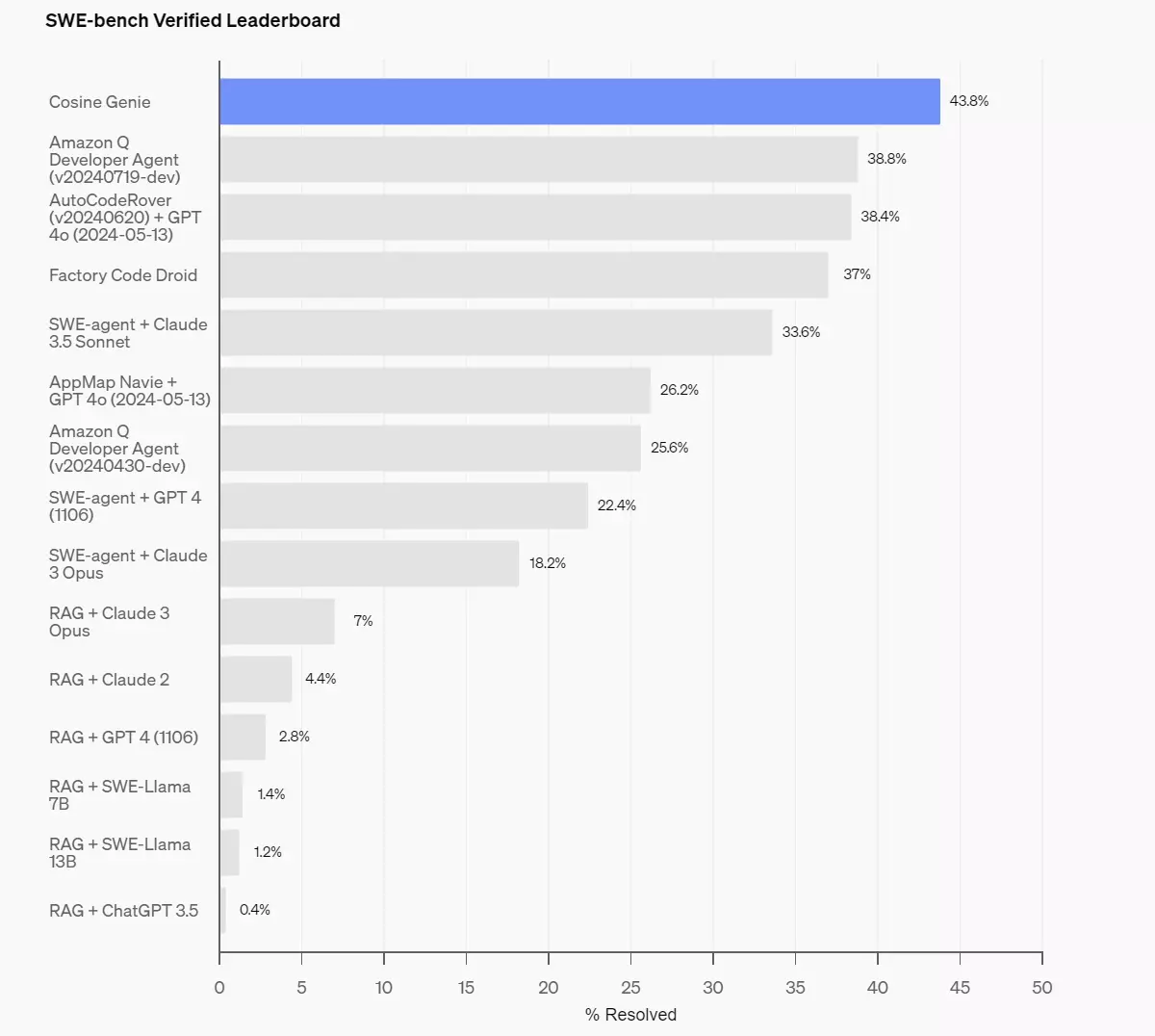
Das Unternehmen führte mehrere Beispiele an, um zu veranschaulichen, wie sich die Feinabstimmung auf die Funktionsweise der Modelle auswirken kann. Es hat einigen seiner wichtigsten Partner bereits die Möglichkeit gegeben, zu demonstrieren, was ein "fokussiertes" GPT-4o leisten kann. Natürlich hat das betreffende OpenAI-Sprachmodell bei diesen Tests hinter den verschiedenen Verbesserungen hervorragende Ergebnisse erzielt.
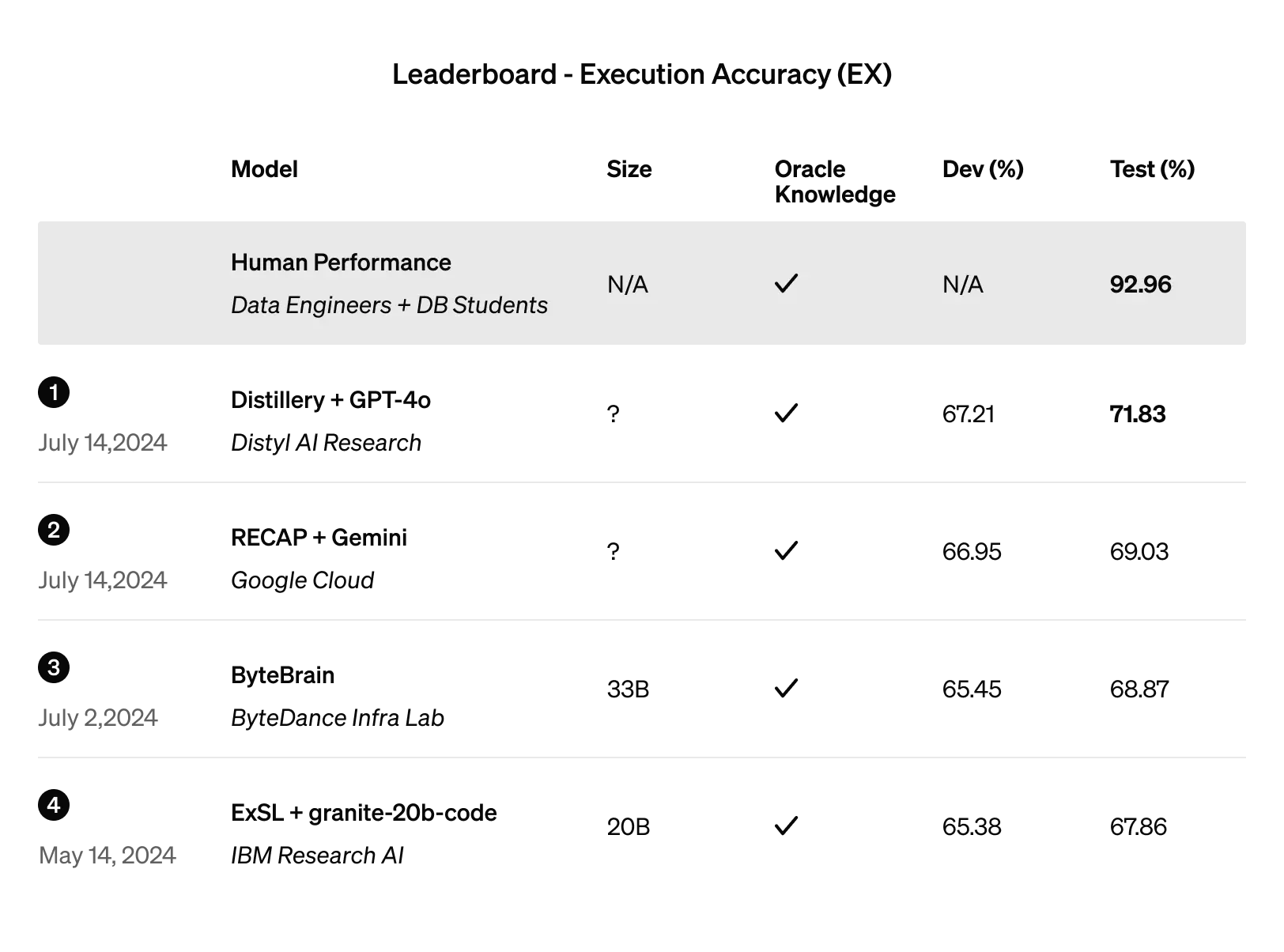
Das Unternehmen sagte auch, dass man sich bei dem fein abgestimmten Modell keine Sorgen machen muss, dass Daten in die falschen Hände geraten könnten. Für Unternehmensinformationen hat sich OpenAI bereits stark für den Datenschutz eingesetzt, und das wird auch hier nicht anders sein. Die für den individuellen Unterricht verwendeten Daten werden mit niemandem geteilt und nicht für das Training des allgemeinen Modells verwendet.
Außerdem wird es eine zusätzliche Sicherheitsebene geben, um sicherzustellen, dass das Modell nicht missbraucht werden kann. Dies ist ebenso wichtig wie die Gewährleistung eines angemessenen Datenschutzes. Die Bedingungen des OpenAI-Vertrags müssen von allen unter allen Umständen eingehalten werden. Das Unternehmen betonte, dass es gespannt sei, was seine Partner mit dem feinjustierten GPT-4o erreichen können.
