Langsamer Start für die ersten ZEN 5-basierten Prozessoren
AMDs Top-Managerin Dr. Lisa Su stellte auf der Computex 2024 die ersten ZEN 5-basierten Client-Lösungen des Unternehmens vor, die RYZEN AI 300 Modelle für das Notebook-Segment und die RYZEN 9000 Prozessoren für das Desktop-Segment. Die mobilen Versionen der RYZEN 9000-Familie, die ursprünglich ab dem 28. Juli 2024 in verschiedenen Notebooks erhältlich sein sollten, wiesen während des Post-Tests einige Probleme auf, so dass die Geschäftsführung beschloss, alle bisher ausgelieferten Modelle zurückzurufen.

Das bedeutet natürlich auch, dass die für den 31. Juli 2024 geplante Markteinführung gestrichen wird. Der RYZEN 5 9600X und der RYZEN 7 9700X kommen am 8. August 2024, der RYZEN 9 9900X und der RYZEN 9 9950X eine Woche später am 15. August 2024. Im Vergleich dazu werden Motherboards mit dem Chipsatz der 800er Serie erst später erscheinen, aber vielleicht noch in diesem Sommer, während Motherboards mit dem Chipsatz der 600er Serie bis dahin verwendet werden sollten, natürlich mit der neuesten UEFI-Firmware.
Das Unternehmen hat bereits auf der Computex 2024 einige Informationen über die RYZEN AI 300- und RYZEN 9000-Serie preisgegeben, aber die Informationen waren zu diesem Zeitpunkt nicht vollständig, so dass viele Fragen zu den Produkten offen blieben. Einige davon wurden Mitte des Monats aufgedeckt, und vor ein paar Tagen wurden weitere wichtige Informationen enthüllt, so dass das Bild nun fast vollständig ist. Dies hat zu der folgenden Zusammenfassung geführt.
Neuerungen in der ZEN 5-Prozessormikroarchitektur
Seit der Einführung der ZEN-Serie im Jahr 2017 ist das Unternehmen bestrebt, die Leistung seiner Prozessorkerne mit jeder neuen Generation der Kernarchitektur schrittweise zu erhöhen. Dies wird zum einen durch die Erhöhung der Taktraten infolge von Änderungen der Streifenbreite erreicht, zum anderen durch den Versuch, die Kernkomponenten der Kerne so kohärent wie möglich zu gestalten, und auch durch die Beachtung des damit verbundenen Anstiegs der Bandbreitenanforderungen für jede Komponente, so dass sie insgesamt in der Lage sind, zweistellige IPC-Steigerungen für jede Generation zu liefern.
Die Kernarchitektur hat sich bei den vergangenen ZEN-Generationen in der Regel nicht so radikal verändert wie bei Intels Plattform, aber es gab einige interessante Technologien, die zu einer Leistungssteigerung beigetragen haben, insbesondere bei Spielen - dies ist beim 3D-V-Cache der Fall. Die vergangenen ZEN-Generationen waren erfolgreich, auch wenn die erste Generation ihre Kinderkrankheiten hatte, die Architektur ist seitdem gut gereift, und die kommende ZEN 5 wird weitere Innovationen und Beschleunigungen bringen. Werden diese ausreichen, um mit den kommenden Intel Arrow Lake-S-Prozessoren zu konkurrieren? Darauf werden wir später eine Antwort haben, aber zunächst lohnt es sich, einen Blick auf die groben Umrisse der Änderungen in der Architektur zu werfen, mit Hilfe von Folien von AMD, die alle wichtigen Informationen enthalten.

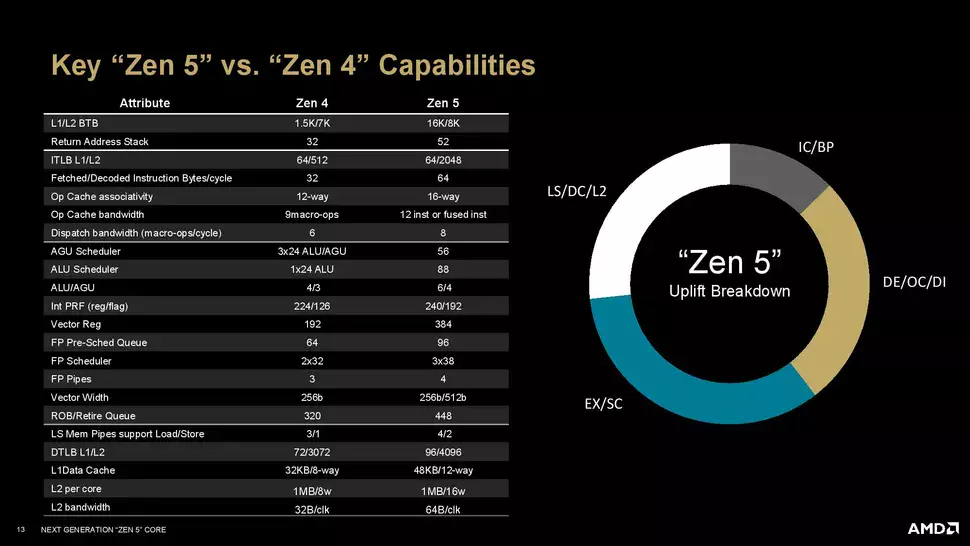
Auf der Grundlage interner Messungen von AMD soll die ZEN 5-Architektur eine IPC-Steigerung von 16 % im Vergleich zu ZEN 4 bieten, wobei es sich hierbei um einen Durchschnittswert handelt: Bei einigen Anwendungen und Arbeitslasten ist die Beschleunigung deutlich geringer, während sie bei anderen Aufgaben deutlich höher ausfallen dürfte. Die Beschleunigung ist größtenteils auf Verbesserungen in allen drei Schlüsselbereichen des Prozessordesigns zurückzuführen, einschließlich Verbesserungen am Front-End, der Execution Engine und dem Load/Store Backend.
Was bedeutet das in der Praxis? Erstens wurde die Verzweigungsschätzung genauer und effizienter gestaltet, da dies eine entscheidende Komponente für die Erhöhung der IPC ist. Durch die Erhöhung der Genauigkeit der Schätzung und die Verringerung der Latenzzeit werden bessere Ergebnisse erzielt, während gleichzeitig alle anderen Komponenten, die zur nahtlosen Nutzung des Potenzials dieser Verbesserung erforderlich sind, verbessert wurden.

In der Abteilung Execution Engine wurden erhebliche Änderungen vorgenommen. So wurde beispielsweise die Breite der Dispatch Retire Queue der Abteilung Integer von 6 auf 8 erhöht. Für die Integer-Engine gibt es jetzt 6 ALUs (Arithmetic Logic Units) mit 3 Multiplikatoren, die vom ALU-Timer gesteuert werden. Gleichzeitig verfügt ZEN 5 über ein größeres Ausführungsfenster, was zu einer weiteren Leistungssteigerung beiträgt - insbesondere bei Workflows mit komplexen Rechenaufgaben, aber auch in anderen Bereichen.

Eine sehr wichtige Änderung gibt es auch bei der Floating Point Unit (FPU), die nun physikalisch mit einer 512-Bit-Spur arbeiten kann, während ZEN 4 eine Dual-Pumped 256-Bit-FPU zur Unterstützung des AVX-512-Befehlssatzes hatte, was damals als energieeffiziente und clevere Lösung galt. Neben der vollen 512-Bit-Datenlane sind sechs Läufer mit zwei taktverzögerten FADDs verbunden. Diese Innovation könnte eine wichtige Rolle bei der Beschleunigung von KI-bezogenen Arbeitsabläufen spielen. An der Desktop-Front ist dies ein wichtiger Aspekt, da keine NPU an Bord ist, aber wir werden später darauf zurückkommen, da es auch in diesem Bereich viel zu besprechen gibt.

Zusätzlich zu den oben genannten Punkten mussten wir auch die Datenbandbreite im Bereich Laden/Speichern erhöhen, so dass der L1-Datencache nun eine Kapazität von 48 KB und einen 12-Wege-Einsatz hat, was eine deutliche Verbesserung gegenüber der vorher verwendeten Lösung mit 32 KB und 8-Wegen darstellt. Die Datenbandbreite zwischen der Fließkommaeinheit (FPU) und dem First-Level-Data-Cache (L1D-Cache) wurde im Vergleich zu ZEN 4 erheblich verdoppelt, und der Data Prefetcher wurde aufgerüstet, um einen schnelleren und zuverlässigeren Datenzugriff und -verarbeitung zu ermöglichen.
Gleichzeitig wurde der Cache der zweiten Ebene nicht verändert, seine Kapazität bleibt bei 1 MB, aber sein Design wurde von 8-way auf 16-way geändert. Dadurch wurde die Datenübertragungsbandbreite des L2-Cache verdoppelt, so dass pro Taktzyklus 64 statt 32 B Daten übertragen werden können. In der Zwischenzeit hat das AMD-Team auch eine Folie zur Verfügung gestellt, die genau zeigt, was sich vom ZEN 4 zum ZEN 5 geändert hat.
So hat sich der IPC, also die Anzahl der Operationen pro Takt, im Vergleich zu ZEN 4 um durchschnittlich 16% erhöht, was - wie oben erwähnt - sicherlich zu begrüßen ist. Das Diagramm unten zeigt auch, wie viel Geschwindigkeitssteigerung bei jeder Anwendung auf der Grundlage der internen Tests erreicht wurde.
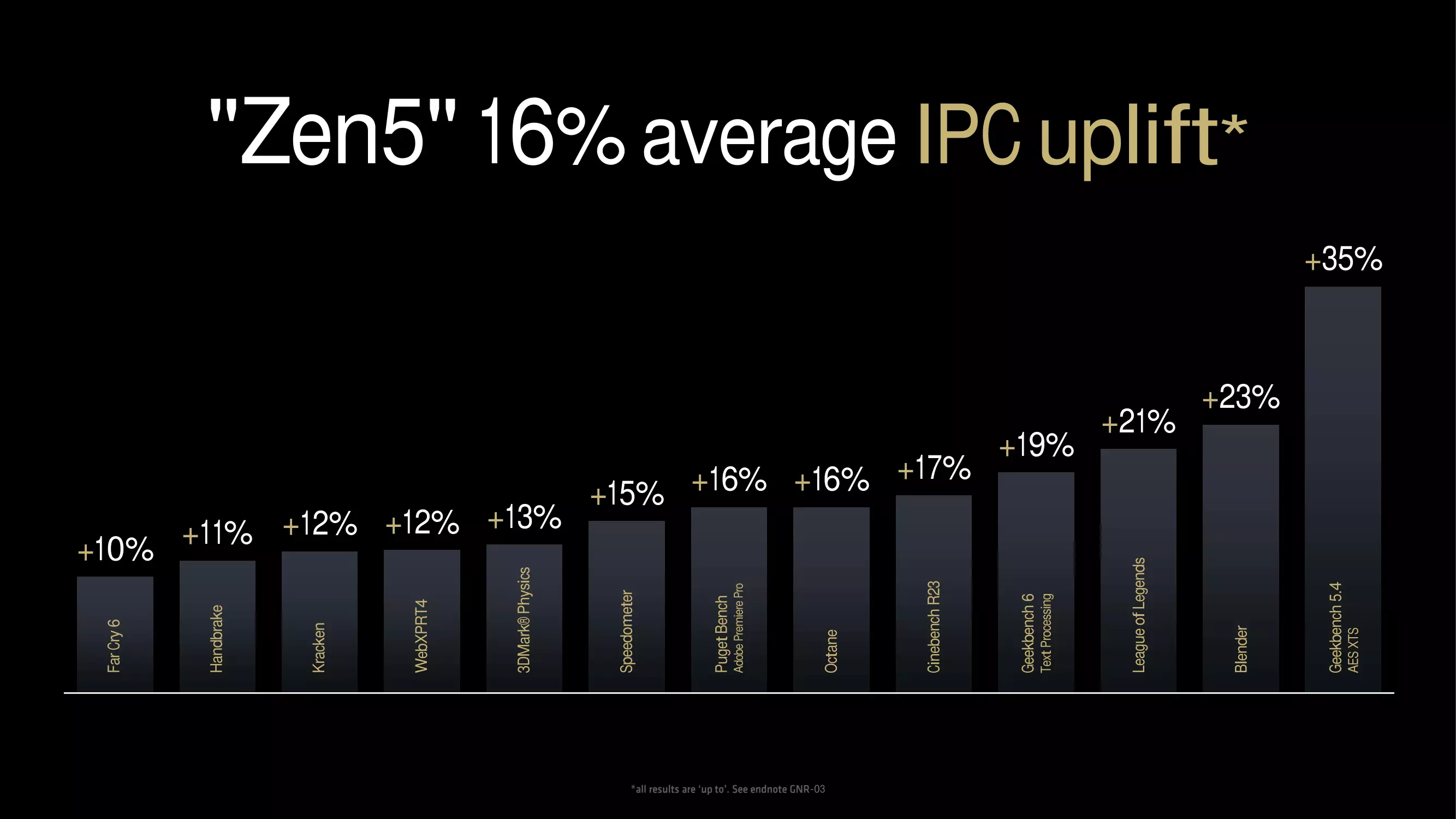
Am einen Ende der Linie befindet sich Far Cry 6, das eine Beschleunigung von 10 % aufweist, während die 16 % Beschleunigung auf den Ergebnissen des Tests unter PugetBench und Adobe Premiere Pro beruhen. Den höchsten Geschwindigkeitszuwachs zeigt der AES XTS Test in Geekbench 5.4, der einen Geschwindigkeitszuwachs von nicht weniger als 35% im Vergleich zu ZEN 4 zeigt. Der letztgenannte Geschwindigkeitszuwachs ist größtenteils auf die aktualisierte FPU zurückzuführen, da dieser Test u.a. auch AVX-512-Unterstützung bietet.

Wie schon beim ZEN 4 wird es auch bei der ZEN 5-Prozessorarchitektur zwei Prozessorkerne geben: den klassischen ZEN 5 in voller Größe und den ZEN 5c, der dichter bibliotheksbasiert ist und weniger Platz benötigt, aber den gleichen begrenzten Taktbereich hat wie seine ZEN 4c-Pendants. Letzteres bedeutet, dass die ZEN 5c-Prozessorkerne in der Regel eine niedrigere maximale Kerntaktfrequenz erreichen als ihre "normalen" Gegenstücke, aber es wird dennoch keinen Unterschied in der Funktionalität zwischen den beiden Kerntypen geben, und die SMT-Unterstützung wird nicht geopfert werden.

Allerdings wird es einen Unterschied in der Fertigungstechnologie geben, denn während die ZEN 5-Cores mit der N4-Technologie von TSMC (4 nm Waferbreite) hergestellt werden, werden die ZEN 5c-Cores mit der N3-Technologie von TSMC (3 nm) des taiwanesischen Halbleiter-Vertragsherstellers gefertigt. Es wird erwartet, dass diese ZEN 5c-Prozessorkerne etwa 25 % weniger Platz benötigen als ihre normalen Gegenstücke, so dass der Unterschied ziemlich signifikant sein wird. Der Unterschied wird also ziemlich groß sein. Nicht so groß wie beim ZEN 4 und ZEN 4c, wo die platzsparenden Kerne 35 % weniger Platz beanspruchten als ihre normalen Gegenstücke.
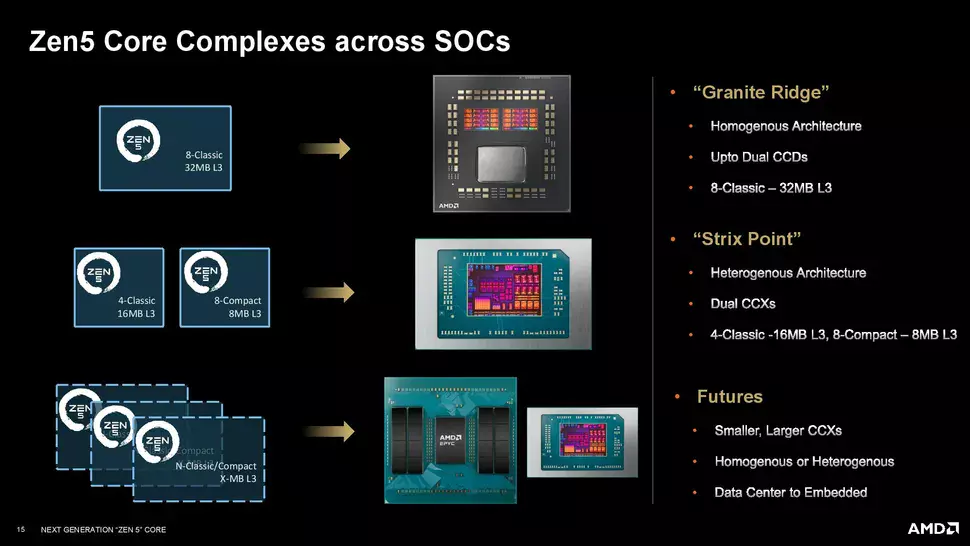
Die ZEN 5c-Prozessorkerne werden natürlich um ein Modell der EPYC-Serie in Form des Turin herum gebaut, der bei maximaler Auslastung 192 ZEN 5c-Prozessorkerne haben soll, aber ZEN 5c-Prozessorkerne werden auch ihren Weg an Bord von Verbraucherprodukten finden, man denke nur an die RYZEN AI 300-Serie, die erst gestern offiziell vorgestellt wurde.
Die RYZEN 9000-Desktop-Prozessoren hingegen werden ausschließlich mit ZEN 5c-Kernen ausgestattet sein, aber die Desktop-APUs werden wahrscheinlich wieder "komprimierte" Kerne aufweisen, wie wir es bereits bei einigen Mitgliedern der RYZEN 8000G-Familie gesehen haben.
So sieht die erste Welle der ZEN 5-Reihe aus - mit den RYZEN 9000-Modellen an der Spitze
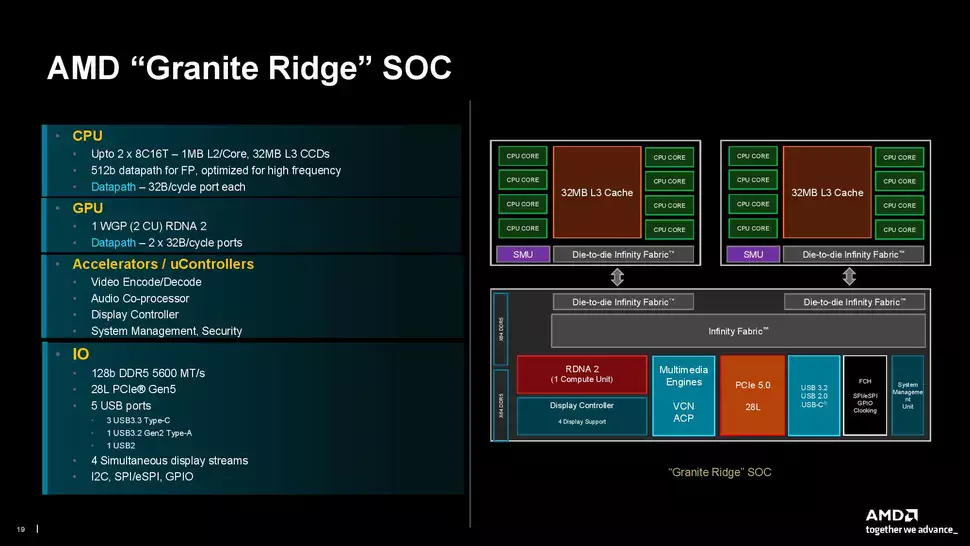
AMD hat eine erste Reihe von Desktop- und Mobilprozessoren herausgebracht, die sich in Bezug auf die Gesamtarchitektur stark voneinander unterscheiden. Wir werden zuerst auf die Desktop-Modelle eingehen, für die die obige Zusammenfassung ausreicht, da sich im Grunde nur die Architektur des Prozessorkerns geändert hat, der ClOD bleibt derselbe. Diese Modelle haben weder eine RDNA 3.5 basierte iGPU noch eine XDNA 2 basierte NPU, diese Extras sind das Privileg der RYZEN AI 300 Serie, zumindest vorerst. Möglicherweise werden sie später zu den Desktop-APUs hinzugefügt, aber es ist nicht bekannt, wann genau sie kommen werden.
Az AMD RYZEN 9000-es sorozatának tagjai
| Merkmal/Modell | Anzahl der CPU-Kerne und Threads | CPU-Kerntakt | CPU-Boost-Taktfrequenz | L2-Cache-Kapazität | L3-Cache-Kapazität | iGPU | Speicher-Unterstützung | TDP-Rahmen |
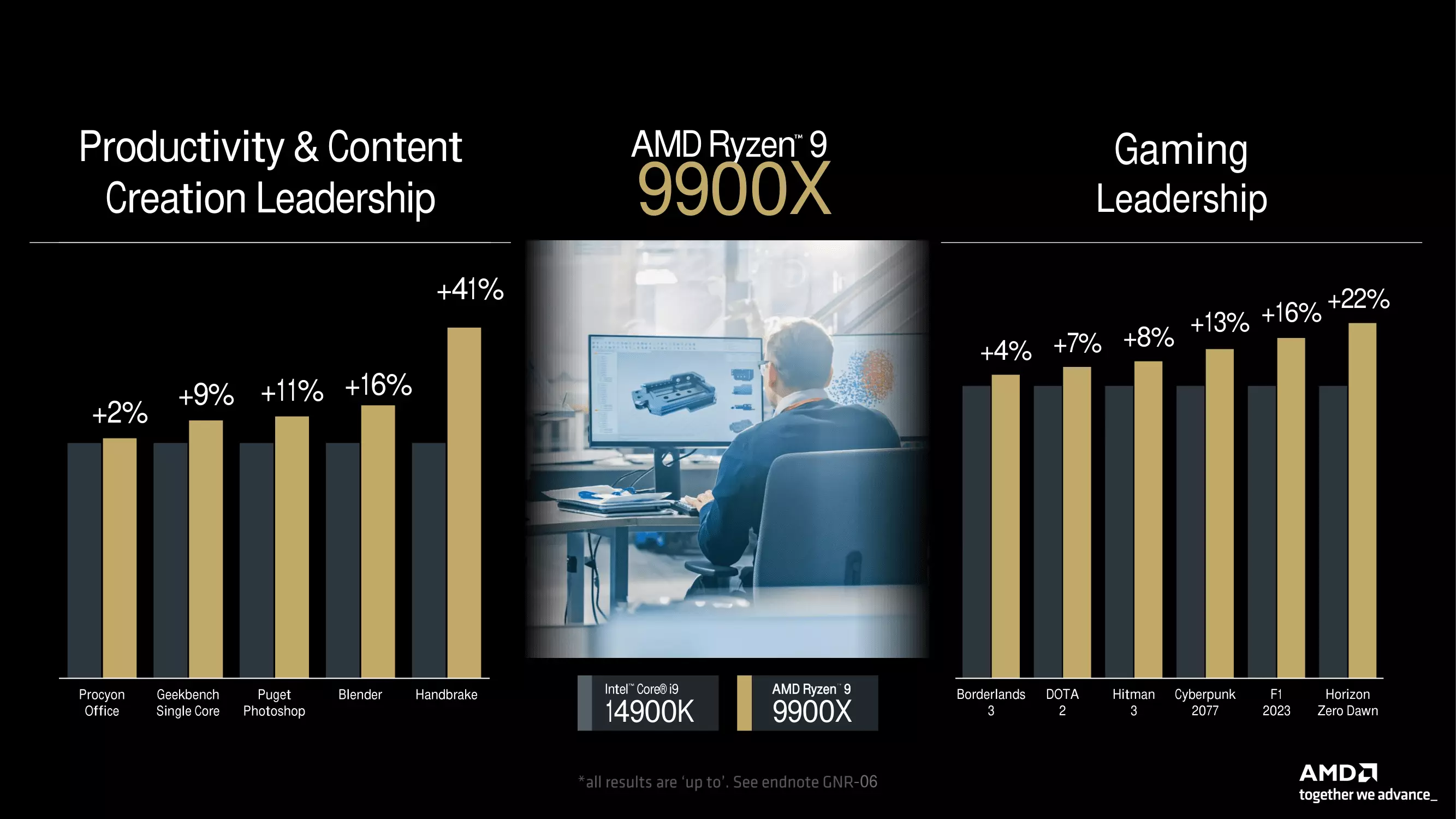
| RYZEN 9 9950X | 16/32 | 4,3 GHz | 5,7 GHz | 16 x 1 MB | 64 MB | 2 CU (RDNA2) | Zweikanal-DDR5-5600 MHz | 170 W |
| RYZEN 9 9000X | 12/24 | 4,4 GHz | 5,6 GHz | 12 x 1 MB | 64 MB | 2 CU (RDNA2) | Zweikanal-DDR5-5600 MHz | 120 W |
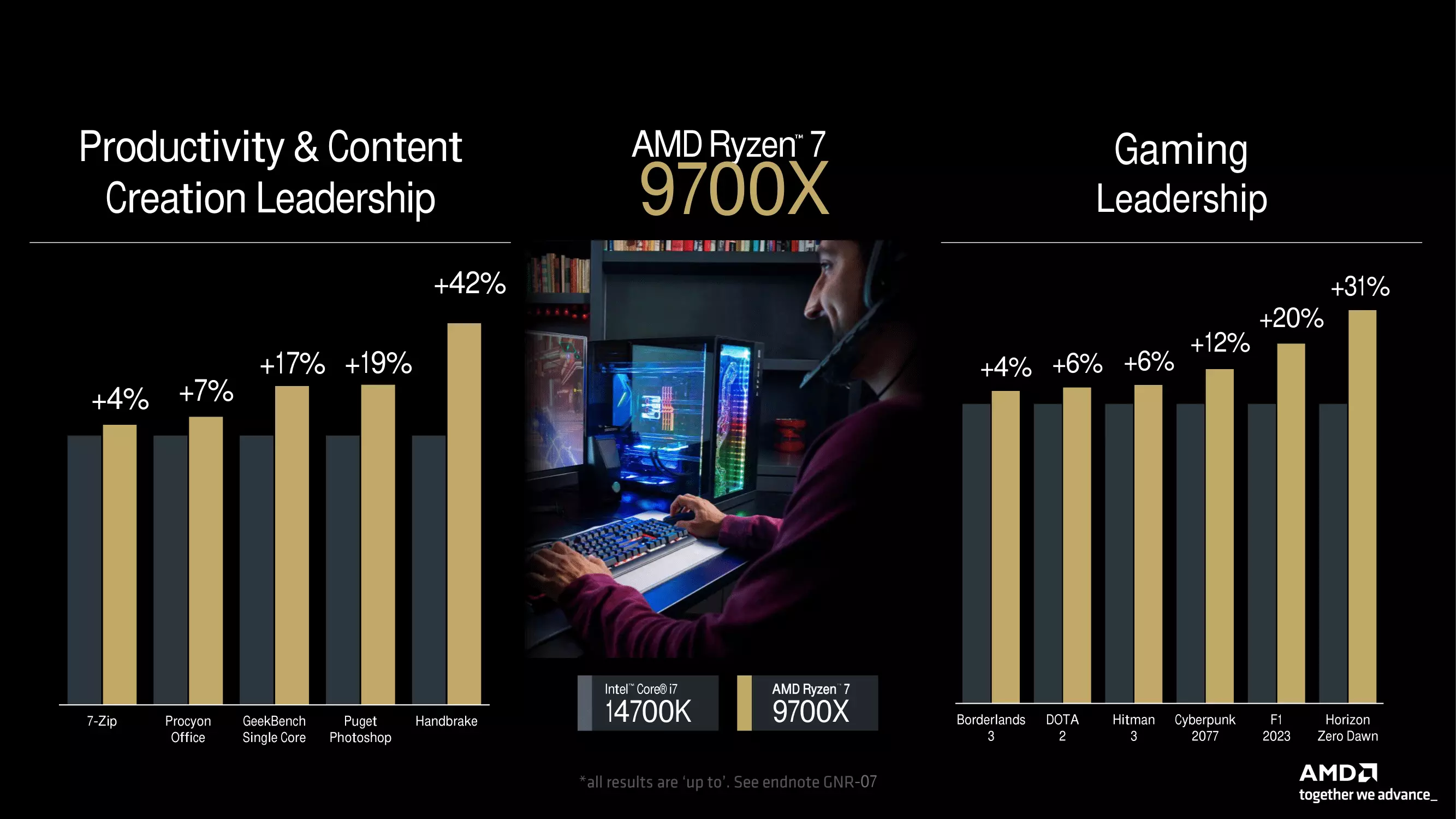
| RYZEN 7 9700X | 8/16 | 3,8 GHz | 5,5 GHz | 8 x 1 MB | 32 MB | 2 CU (RDNA2) | Zweikanal-DDR5-5600 MHz | 65 W |
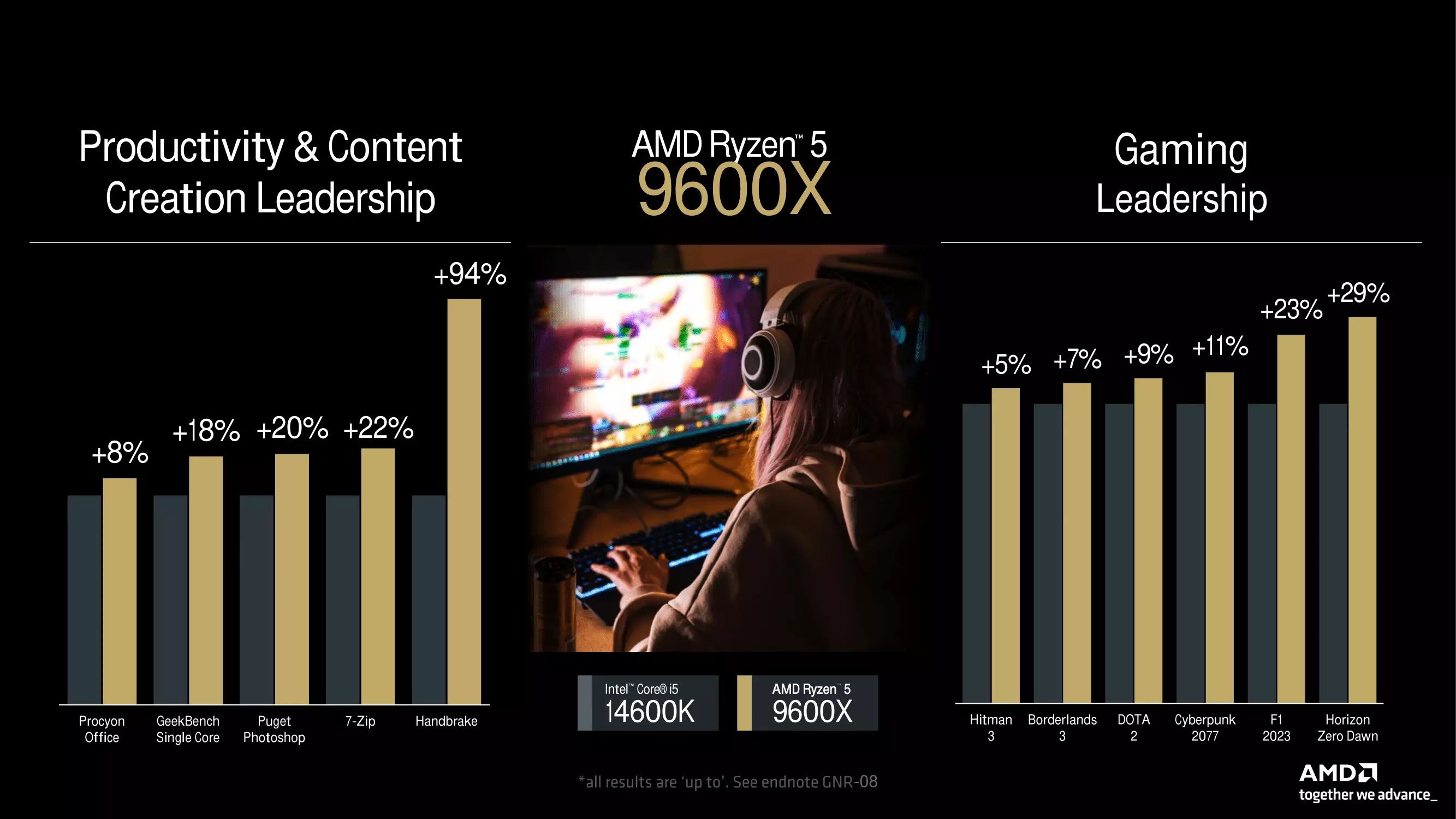
| RYZEN 6 9600X | 6/12 | 3,9 GHz | 5,4 GHz | 6 x 1 MB | 32 MB | 2 CU (RDNA2) | Zweikanal-DDR5-5600 MHz | 65 W |
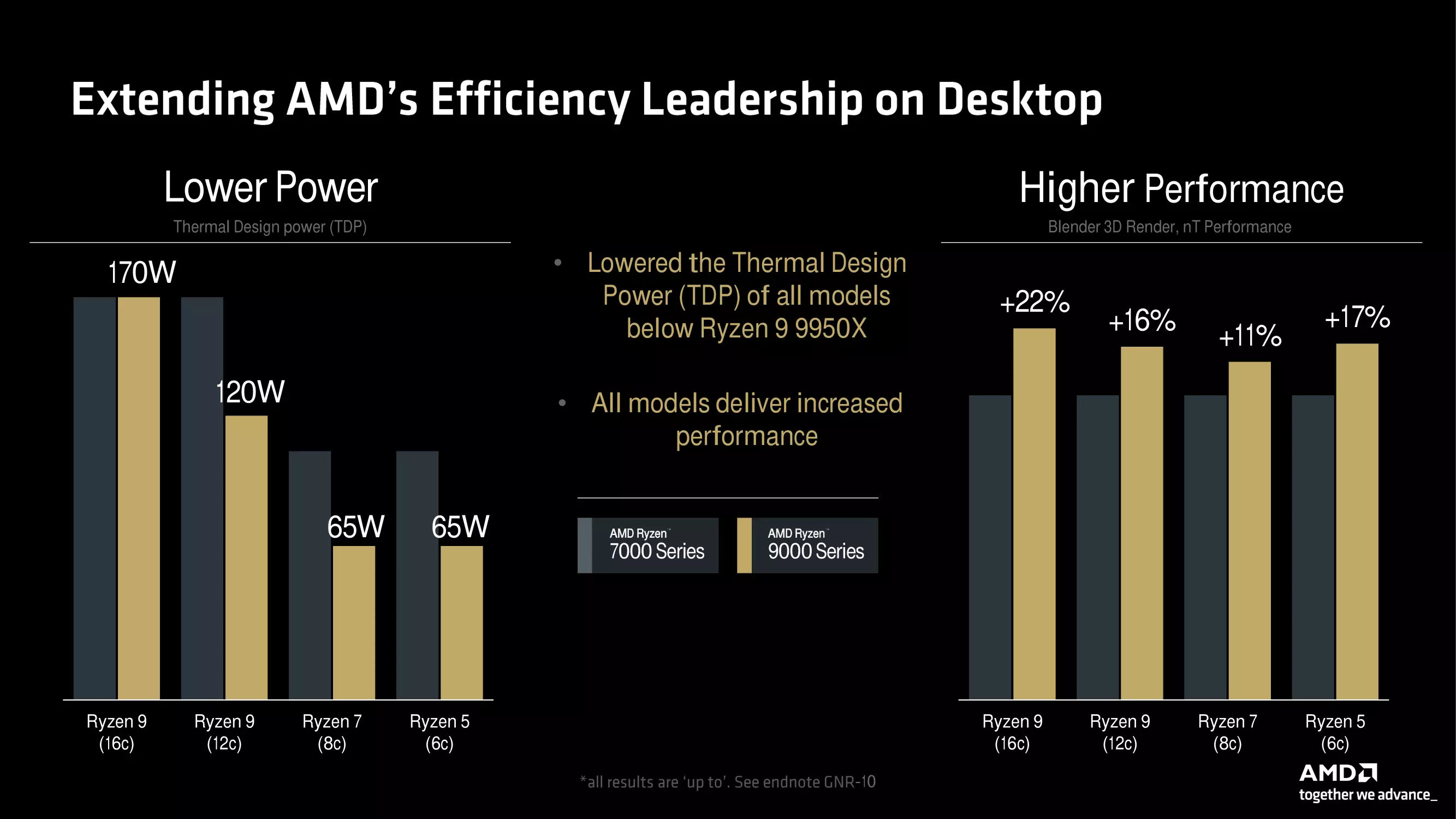
Von den neuen Prozessoren behält nur der RYZEN 9 9950X die TDP der vorherigen Generation bei, die anderen Modelle haben einen niedrigeren TDP-Rahmen, aber gleichzeitig ist die Leistung dank der oben beschriebenen neuen Funktionen gestiegen. Die Ingenieure des Unternehmens haben auch sehr darauf geachtet, den Gesamtwärmewiderstand der neuen Prozessoren im Vergleich zu den Vorgängergenerationen zu senken, was zu einer Reduzierung der Betriebstemperaturen beiträgt und die Leistung weiter verbessern kann, da jedes Produkt länger im maximalen Turbo-Boost-Taktbereich bleiben kann.
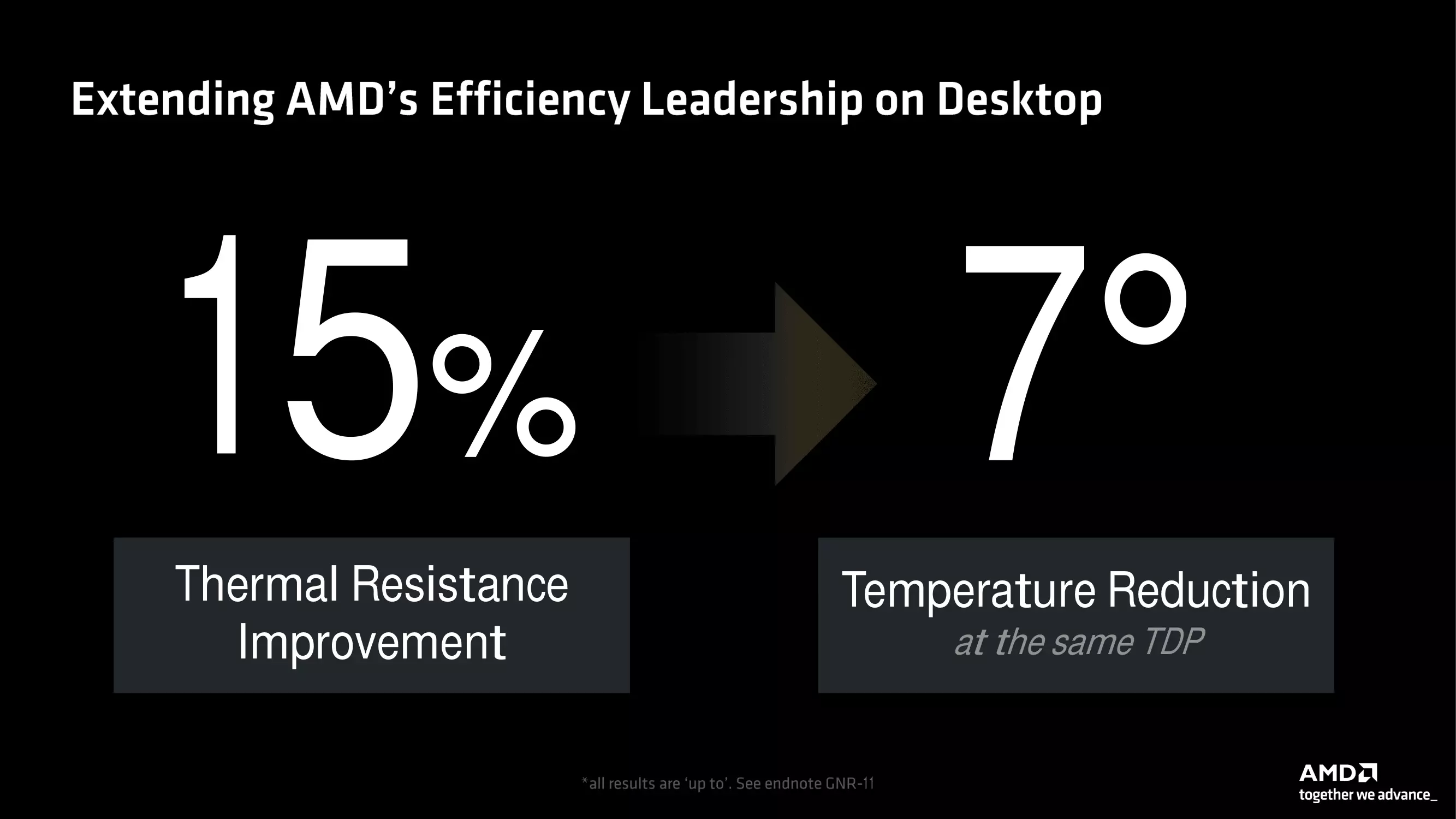
Leider wurden keine Details darüber genannt, wie diese Verbesserung erreicht wurde, sondern nur, dass der Wärmewiderstand um 15 % gesenkt wurde, was bei gleichem TDP-Rahmen zu einer Senkung der Betriebstemperaturen um 7 Grad Celsius führt. Der Hersteller hat natürlich auch einige interne Testergebnisse präsentiert, die die Leistung einiger Mitglieder der RYZEN 9000-Familie mit Intels aktuellen Prozessoren der Core-Serie der 14. Alle wichtigen Folien finden Sie in der untenstehenden Galerie. Da es sich jedoch um interne Testergebnisse handelt, sind sie mit Vorsicht zu genießen.
Die unabhängigen Tests werden zeigen, wie jede neue Version im Vergleich zu ihren Konkurrenten in ihrer Kategorie und zu den Vorgängermodellen in einem breiteren Spektrum von Anwendungen und Spielen abschneidet. Es sollte auch nicht vergessen werden, dass die wirkliche Konkurrenz für die RYZEN 9000-Serie nicht die Intel Core-Angebote der 14. Generation sein werden, d. h. nicht die Raptor Lake Refresh-Serie, sondern die Arrow Lake-S-Modelle, die später in diesem Jahr kommen und definitiv wettbewerbsfähiger sein werden als die Mitglieder der Raptor Lake Refresh-Serie.
Es ist auch eine Tatsache, dass es in der kommenden Zeit weitere Neuigkeiten von AMD geben wird, da die RYZEN 9000X3D-Modelle, die sich an Gamer richten, ebenfalls in das Sortiment aufgenommen werden. Es wird erwartet, dass diese Modelle früher auf den Markt kommen werden, als man aufgrund der Praxis der vorherigen Generationen erwarten würde. Bei letzterem handelt es sich natürlich nur um ein Gerücht, das noch nicht von einer offiziellen Quelle bestätigt wurde.
Die neuen Prozessoren werden von einer neuen Familie von Chipsätzen begleitet
AMDs Granite Ridge-basierte Prozessoren der RYZEN 9000-Serie werden natürlich mit Sockel AM5 gekapselt sein, so dass sie neben der neuesten UEFI-Firmware auch mit bestehenden Motherboards, die auf dem Chipsatz der 600er-Serie basieren, verwendet werden können. Zu Beginn wird es nicht wirklich viele andere Optionen geben, da Gerüchten zufolge zunächst nur die neue Prozessorgeneration auf den Markt kommen wird, während die Motherboards erst später folgen.
In der Zwischenzeit wurde festgestellt, dass die RYZEN 9000-Modelle nicht mehr lieferbar sind und von Partnern und Händlern zurückgerufen wurden. Der 31. Juli 2024 wurde verschoben, so dass der RYZEN 5 9600X und der RYZEN 7 9700X am 8. August 2024 und der RYZEN 9 9900X und der RYZEN 9 9950X am 8. August 2024 auf den Markt kommen werden. Wann genau die Motherboards mit dem 800er-Chipsatz erscheinen werden, ist noch nicht bekannt, aber zumindest wird es nicht so lange dauern, wie ursprünglich geplant, bis die Prozessoren und Motherboards auf den Markt kommen.

Die Motherboards mit 800er-Chipsatz, zu denen die Modelle X870E, X870, B850 und B840 gehören, werden sich kaum von ihren Pendants der 600er-Serie unterscheiden. Sie werden weiterhin auf dem Promontory 21-Chip basieren, der von ASMedia entwickelt und hergestellt wird, aber mit fortschrittlicheren externen Treibern als die 600er-Serie, wie z. B. Wi-Fi 7-Unterstützung, und einem USB4-Anschluss am oberen Ende, wie AMD es von den Herstellern verlangt.
Der X870E wird im Wesentlichen ein Rebranding des X670E sein, während der X870 ein Rebranding des B650E sein wird. Bei der PCI-Express-Unterstützung wird es keine Unterschiede zwischen den beiden Chipsätzen geben, d. h. beide werden PCI-Express-5.0-Unterstützung für die GPU und M.2-PCIe-NVMe-Steckplätze bieten, aber der X870E wird mehr PCI-Express-Lanes an Bord haben. USB4 wird für diese Motherboards im Prinzip obligatorisch sein.

Der B850 wird im Wesentlichen eine neu zugewiesene Version des beliebten B650 sein, der standardmäßig PCI Express 4.0-Unterstützung für die Grafikkarte bietet, aber Motherboard-Hersteller werden die Möglichkeit haben, für diesen Steckplatz auf PCI Express 5.0 zu wechseln. Die M.2-PCIe-NVMe-Steckplätze werden weiterhin auf PCI Express 5.0 basieren, aber der USB4-Anschluss wird nicht mehr benötigt. Der B840 ist im Wesentlichen ein Einsteiger-Chipsatz mit nur PCI Express 3.0-Unterstützung für den PCIe x16-Steckplatz für Grafikkarten und dem Verlust des CPU-Tunings. Dieser Chipsatz wird den A620 ersetzen.
Motherboards mit dem 800er-Chipsatz werden voraussichtlich noch in diesem Sommer auf den Markt kommen, allerdings etwas später als die Mitglieder der RYZEN 9000er-Serie. Dementsprechend werden sie zunächst nur für die Verwendung mit X670E-, X670-, B650E-, B650- oder A620-basierten Boards verfügbar sein, natürlich nach einem BIOS-Update.
RDNA 3.5 iGPU-Architektur ist im Kommen

Wie von AMD bereits angekündigt, wird diese neue Architektur nur für die mobilen APUs der RYZEN AI 300 Serie verfügbar sein, während die RYZEN 9000 Serie weiterhin die bekannte iGPU mit 2 CUs und 128 Streams - basierend auf RDNA 2 - verwenden wird. Darauf deutet die Tatsache hin, dass sich die RZYEN 9000 Prozessoren laut AMDs offiziellem Statement im Wesentlichen nur in Bezug auf die Anzahl der Kerne von ihren Vorgängergenerationen unterscheiden werden, wobei das ClOD-Chiplet weiterhin die gleiche 6 nm breite Lösung sein wird, die wir bereits von den RYZEN 7000 Modellen gewohnt sind. Inzwischen ist auch das offizielle Slide eingetroffen, was bedeutet, dass die obige Annahme richtig war: die RDNA 2 basierte iGPU mit 128 Stream Units wird für die RYZEN 9000 Serie beibehalten.
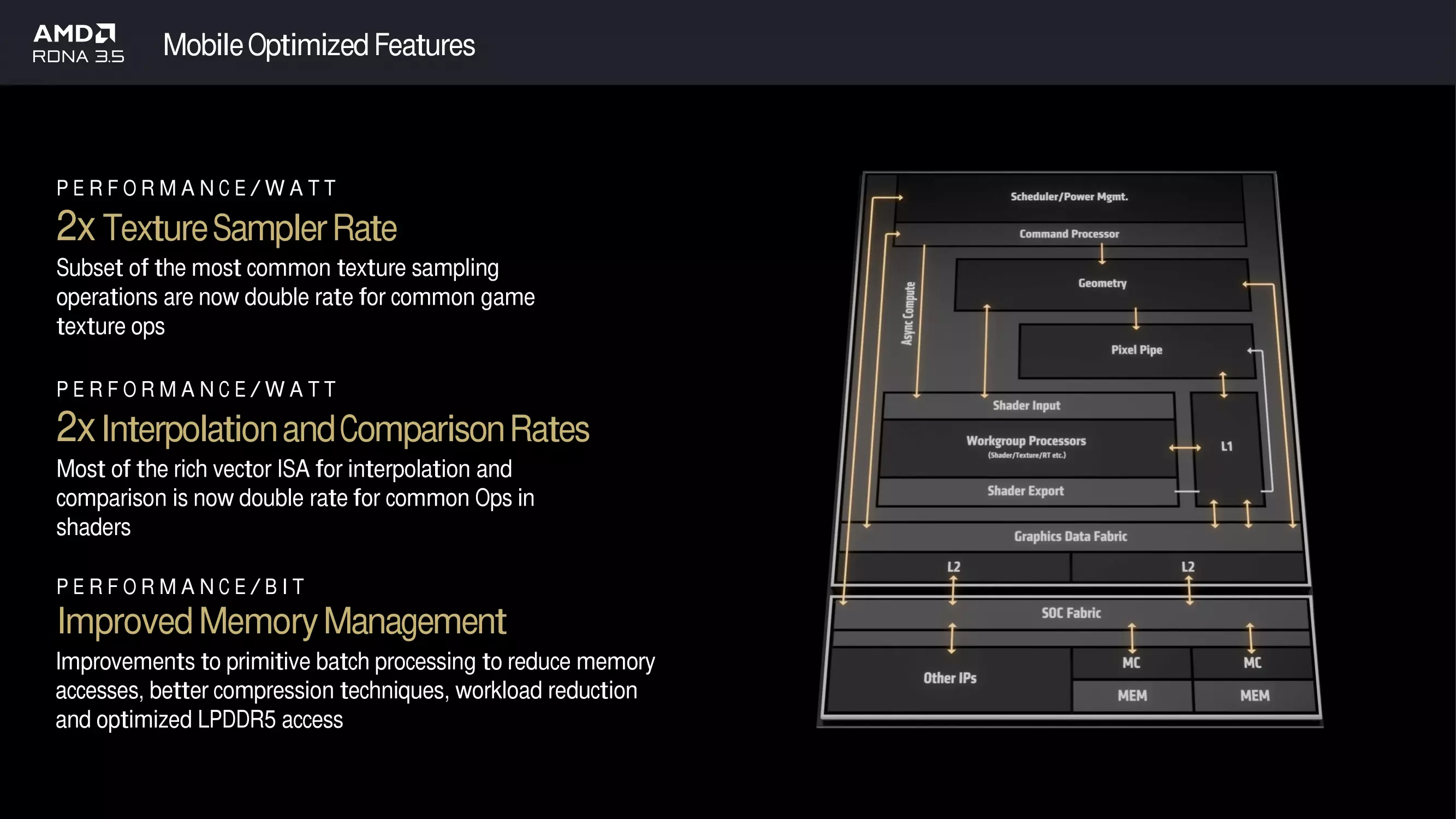
Nun zurück zur RDNA 3.5 Architektur, die eine interessante Entwicklung darstellt. Der Grund, warum sie nicht den Namen RDNA 4 verdient hat, liegt darin, dass sie auf der Grundlage der RDNA 3-Architektur mit einigen Modifikationen aufbaut, die insgesamt zu einer Leistungsverbesserung beitragen, aber der Kern des SIMD-Designs wurde nicht verändert. Das Hauptaugenmerk lag auf der Steigerung der Energieeffizienz, was zu einer höheren Leistung führte.

Die in den Strix Point APU-Einheiten verwendeten iGPUs sind um insgesamt eine Shader Engine herum aufgebaut, die insgesamt 8 Work Group Processors (WGPs) enthält und insgesamt 16 CU-Arrays für das System bereitstellt - eine erhebliche Verbesserung gegenüber der RDNA 3-basierten Lösung, bei der bei maximaler Bereitstellung nur 12 CUs zur Verfügung standen. Die 16 CU-Arrays enthalten insgesamt 1024 Stream Units, mit 16 RT-Beschleunigern und 32 AI-Beschleunigern. Die iGPU kann insgesamt 16 RoP-Einheiten verarbeiten. Die Leistung der neuen iGPU kann im Vergleich zur RDNA 3-basierten Phoenix iGPU mit 12 CU-Arrays um etwa 30 % verbessert werden, bei ähnlichem Stromverbrauch, was sehr gut klingt. Die iGPU selbst ist in der Lage, eine Single-Precision-Rechenleistung von über 11 TFLOP/s bei 2,9 GHz zu erreichen.
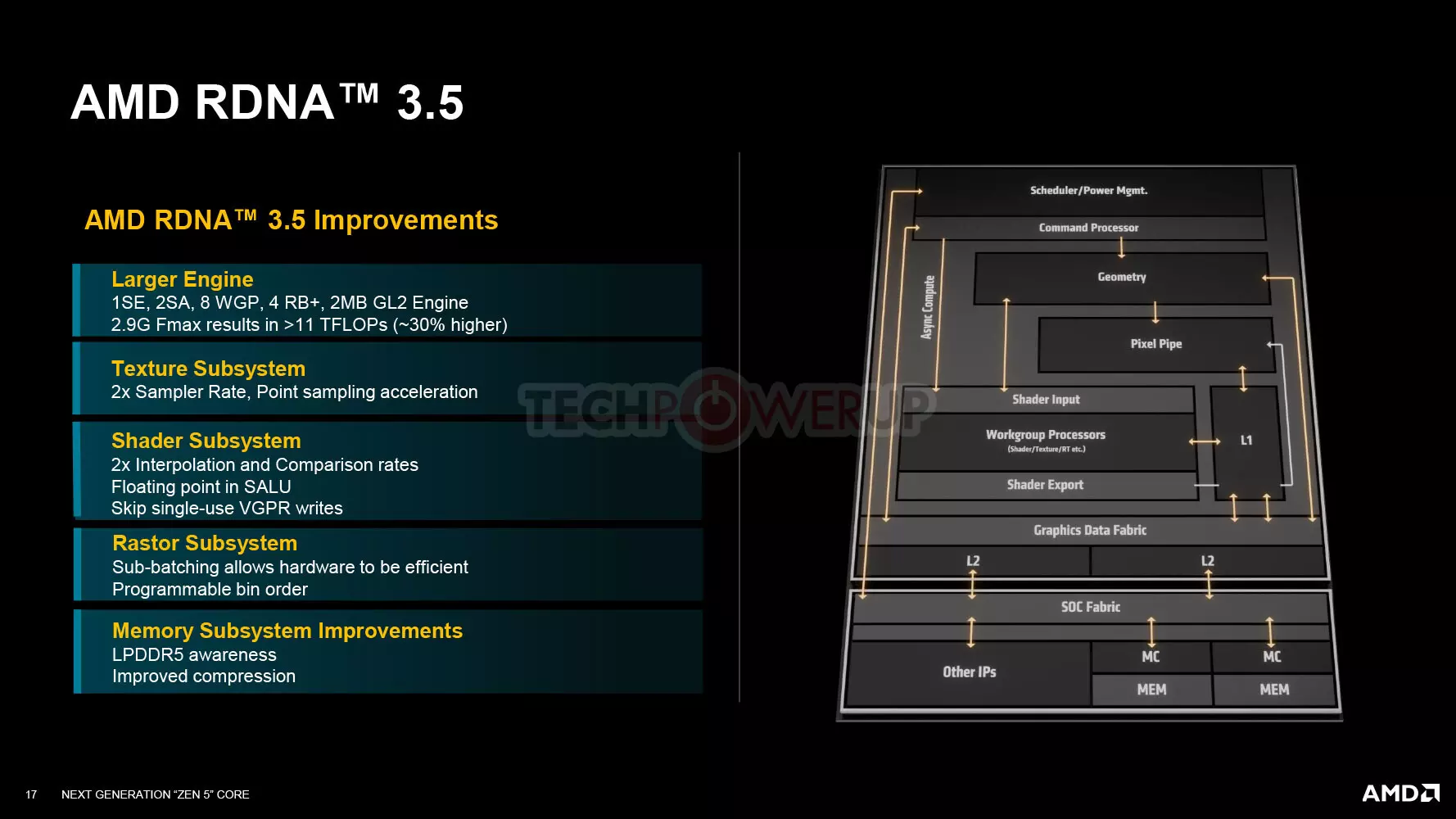
Die Texturabtastrate wurde verdoppelt, was zu einer erheblichen Leistungssteigerung führt, gleichzeitig wurden aber auch die Interpolations- und Kompressionsraten im Vergleich zu RDNA 3 verdoppelt. Dies ebnet den Weg für höher aufgelöste Spiele und die Verwendung von saubereren, höher aufgelösten Texturen, während gleichzeitig die Leistung ausreichend hoch ist, um den Titel in der höheren Auflösung und mit detaillierteren Texturen zu spielen.
Es wurde auch darauf geachtet, den Betrieb des Speichersubsystems zu optimieren, was bedeutet, dass das System beispielsweise weniger Speicherzugriffe für Primitive Batch Processing benötigt, aber auch die Komprimierungstechniken wurden verbessert, und die Arbeitslast von Workflows wurde reduziert und der Speicherzugriff von LPDDR5 wurde optimiert. Letzteres, d. h. LPDDR5, funktioniert etwas anders als GDDR6, so dass sich die Optimierungen in der Praxis auf seine Besonderheiten konzentrierten.
Insgesamt sollten diese Änderungen und Optimierungen zu einem energieeffizienteren Betrieb, einer längeren Akkulaufzeit und einer besseren Speichernutzung führen, was definitiv eine gute Nachricht ist.
Große Verbesserungen auch bei der NPU: XDNA 2 Grundlagen, enormer Leistungsschub

Die NPU spielt heute eine immer wichtigere Rolle im Prozessor-Segment, und ihre Bedeutung wird noch zunehmen, da es immer mehr Anwendungen gibt, die ihr Potenzial nutzen können. Microsoft hat bereits eine neue Kategorie für Konfigurationen entwickelt, die über eine ausreichend leistungsfähige NPU verfügen: Sie können in die Kategorie Copilot+ PC eingeordnet werden, in der der Einstiegsbereich der NPU mindestens 40 TOPs Leistung aufweist. Dies wird von der RYZEN AI 300 Serie mit ihren 50 TOPs deutlich übertroffen, aber wie AMD-Offizielle bereits angedeutet haben, werden die RYZEN 300 AI-basierten Produkte zunächst nicht die Funktionalität der Copilot+ PC-Kategorie haben, aber das wird sich später ändern.
Bei AMD sind NPUs seit der Veröffentlichung der RYZEN 7040 Serie oder Phoenix APUs verfügbar. Damals konnte die Lösung, die auf der ersten Generation der XDNA-Architektur aufbaut, nur 10 TOPs Leistung erreichen, aber mit der Veröffentlichung der RYZEN 8040 Serie oder Hawk Point APUs gab es eine 60%ige Beschleunigung in diesem Bereich, aber die Architektur hat sich nicht geändert. Die NPU selbst basiert auf der Xilinx-Technologie, aus der sich die XDNA-Architektur entwickelt hat - Xilinx wurde 2020 vom Unternehmen übernommen.

Die XDNA 2-Architektur ist eine ziemlich große Veränderung und bietet eine Leistungssteigerung von nicht weniger als dem Fünffachen (10 TOPs vs. 50 TOPs) im Vergleich zur XDNA 1-basierten NPU. Erreicht wurde dies durch die Platzierung von zwei MACs auf jeder AI-Engine-Kachelplatine anstelle von einem, aber auch durch die Vergrößerung des On-Chip-Speichers um das 1,6-fache, die Verbesserung der nicht-linearen Unterstützung und die Aufnahme von Block FP16-Unterstützung in das Repertoire. Letzteres kombiniert laut AMD die Geschwindigkeit von 8-Bit-Berechnungen mit der Genauigkeit von 16-Bit-Berechnungen, was sich nicht schlecht anhört, aber in der Tat nicht ganz auf Augenhöhe mit 16-Bit ist, aber sehr nahe dran.

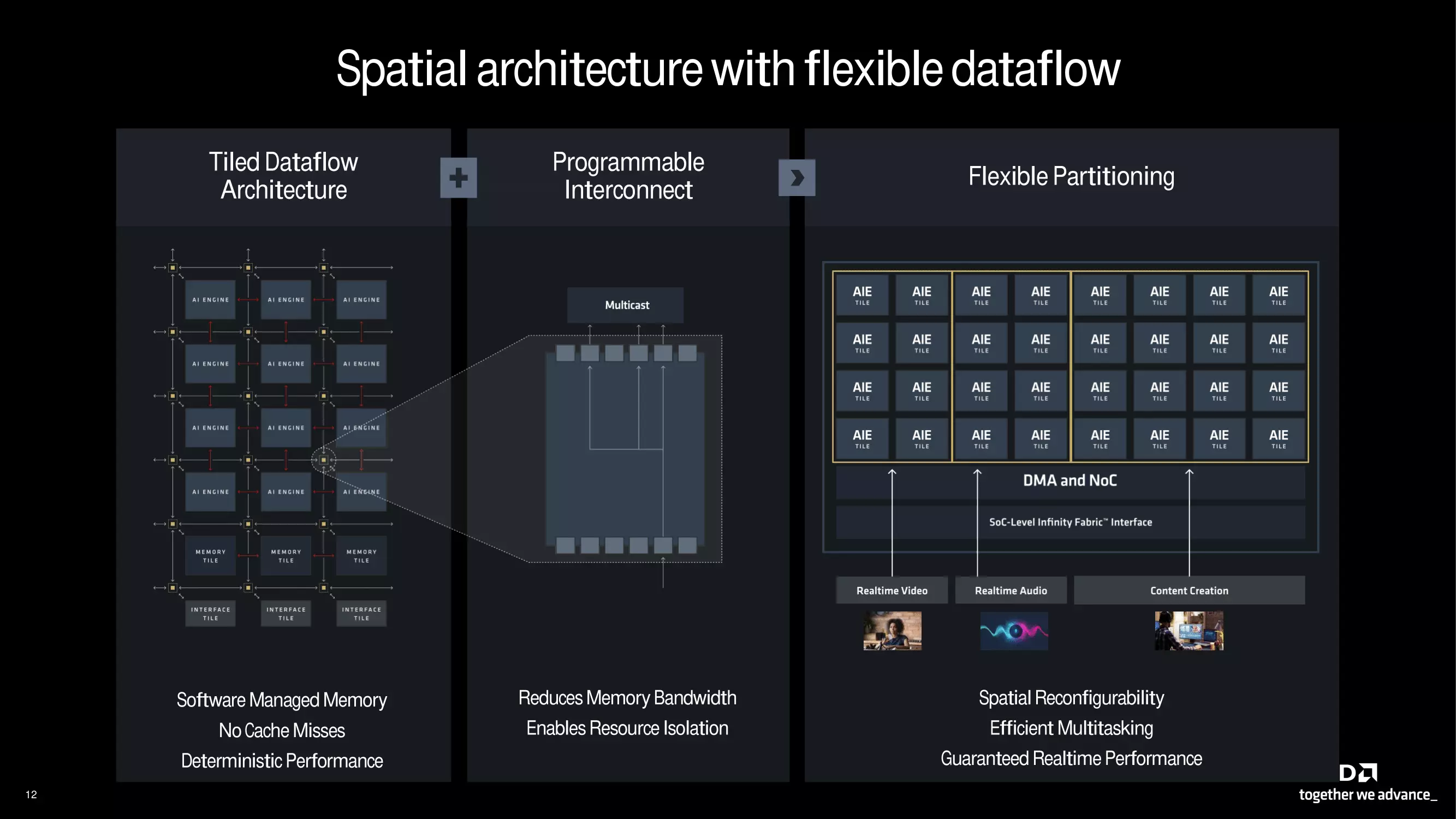
Die leistungsstärkere Kachelsektion der KI-Engine besteht nun aus 32 statt 20 Kacheln und nutzt gleichzeitig eine Reihe kreativer Technologien, um die Nutzung der verfügbaren Ressourcen zu optimieren. Wie sein Vorgänger wird die neue Architektur von AMD als räumliche Architektur beschrieben, bei der die Flexibilität ein zentrales Designkriterium ist: Die Architektur ist flexibel partitionierbar und die Verbindungen sind programmierbar.

Die Kachelstruktur des Datenflusses ermöglicht eine effizientere Speichernutzung, während die flexible Struktur und die programmierbaren Verbindungen dafür sorgen, dass das System Ressourcen nach Bedarf zuweisen kann, um der aktuellen Arbeitslast am besten zu entsprechen. Die flexible Partitionierung ermöglicht die effiziente Ausführung mehrerer Aufgabentypen gleichzeitig, darunter KI-Deduktion, Audio- oder Videoverarbeitung in Echtzeit und die Produktion von Inhalten, um nur einige zu nennen.
Die nächste Generation ist die RYZEN AI 300 Familie
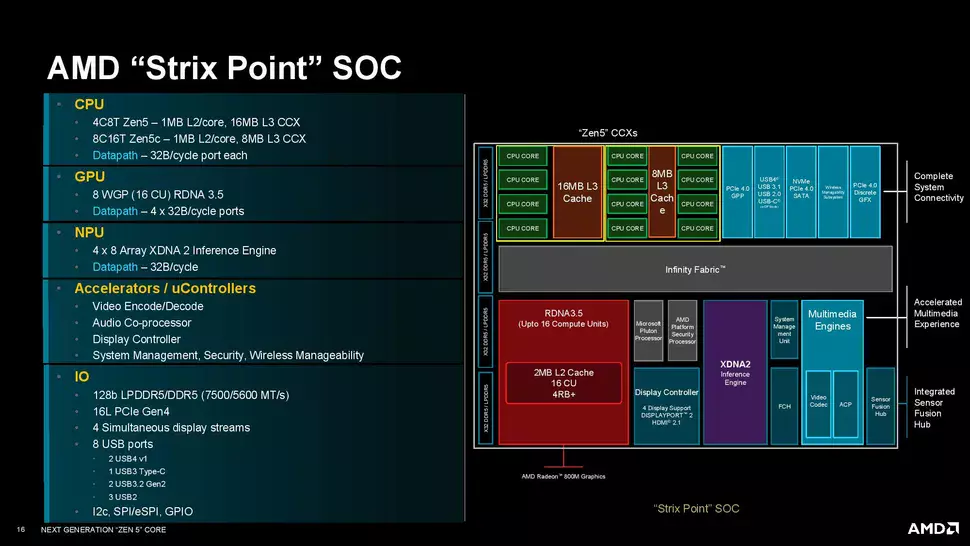
Diese mobilen APUs werden im Wesentlichen mit Intels kommender Core-Ultra-200V-Serie konkurrieren, d.h. sie werden Rivalen der Lunar-Lake-Familie sein. Wie bereits erwähnt, werden diese mobilen APUs eine hybride Architektur haben, d.h. sie werden nicht nur ZEN 5 sondern auch ZEN 5c basierte Prozessorkerne haben. Das AMD-Team hat anfangs nicht genau verraten, wie die SoC-Prozessorkerne aufgebaut sein werden, aber glücklicherweise wurde dies vor kurzem enthüllt, so dass es kein Geheimnis ist, dass sie wieder die beiden CCX-Arrays verwenden, die zuletzt vor zwei Generationen verwendet wurden, aber nur für Standard-Prozessorkerne.

Für die Strix Point APUs bedeutet die duale CCX-Array-Architektur, dass ein CCX-Array die Standardgröße der ZEN 5-Prozessorkerne (bis zu 4) enthält, während das andere CCX-Array die ZEN 5c-Prozessorkerne (bis zu 8) enthält. Die beiden CCX-Arrays sind über den üblichen Infinity Fabric Interconnect mit dem Chip verbunden. Die Bedingungen für den Zugriff auf den Interconnect sind für beide CCXs gleich: Sie können beide 32 Bit Daten lesen und 16 Bit Daten pro Taktzyklus über denselben Datenpfad schreiben. Es gibt noch weitere Unterschiede zwischen den beiden CCX-Arrays, nicht nur bei den Typen der Prozessorkerne, sondern auch bei der Kapazität des gemeinsam genutzten Cache der dritten Ebene.
Das CCX mit ZEN 5-Prozessorkernen hat Zugriff auf insgesamt 16 MB gemeinsam genutzten Tertiärcache, während das CCX mit ZEN 5c-Prozessorkernen mit insgesamt 8 MB gemeinsam genutztem Tertiärcache nur halb so viel zur Verfügung hat. Beim sekundären Cache oder L2-Cache gibt es keine Unterschiede: Sowohl die ZEN 5- als auch die ZEN 5c-Kerne haben Zugriff auf 1 MB dedizierten sekundären Cache.
Es wird erwartet, dass die ZEN 5-Prozessorkerne in der Lage sind, Taktraten von weit über 5 GHz zu erreichen, während ZEN 5c-basierte Lösungen eine insgesamt niedrigere maximale Boost-Taktrate von knapp 5 GHz und niedrigere Kerntaktraten haben werden, dafür aber wesentlich stromsparender sind, was im Notebook-Segment ein wichtiger Aspekt ist. Ein sehr wichtiger Zusatz, der erst kürzlich bekannt wurde, ist, dass die Strix Point Prozessoren im Vergleich zu den Granite Ridge Prozessoren, deren ZEN 5 Prozessorkerne über eine 512-Bit FPU verfügen, nur über eine 256-Bit Datenbandbreite verfügen, was anscheinend nicht durch eine Halbierung der verfügbaren Bandbreite durch deren Deaktivierung erreicht wurde, sondern durch die Schaffung separater Prozessorkerne mit einer 256-Bit FPU. Dies könnte auch bedeuten, dass die auf ZEN 5 und ZEN 5c basierenden Prozessorkerne für die Strix Point APU-Einheiten kleiner sein werden als für die Granite Ridge-Modelle, die nur ZEN 5-Prozessorkerne mit 512-Bit-FPUs haben.
Die Leistung der AVX512-Unterstützung, die von den Prozessorkernen in den Strix Point APU-Einheiten bereitgestellt wird, wird wahrscheinlich nicht so kritisch sein wie bei den Granite Ridge-Prozessoren, da erstere auch eine ausreichend leistungsstarke NPU enthalten, um bei KI-ähnlichen Arbeitslasten effektiv eingesetzt zu werden, während diese Komponente bei den Granite Ridge-Modellen fehlt. Andererseits haben die AMD-Ingenieure durch den Verzicht auf die volle 512-Bit-Datenlane auch wertvollen Platz gespart, was besonders bei mobilen APU-Einheiten ein wichtiger Vorteil sein kann. Möglicherweise könnte dies die Änderung erklären, aber diese Behauptungen basieren vorerst nur auf Vermutungen und wurden von AMD nicht bestätigt.
Es ist noch nicht klar, wie die Unterstützung für die AVX512- und AVX-VNNI-Befehlssätze in den Strix Point APU-Einheiten implementiert werden wird - es ist nicht ausgeschlossen, dass sie mit 256-Bit-FPUs auf die gleiche Weise wie in den ZEN 4-basierten Modellen dual gepumpt werden.

Nicht fehlen wird die VCN (Video Core Next)-Engine zum Kodieren und Dekodieren verschiedener Videoinhalte, aber wir bekommen auch einen Audio-Coprozessor, der im Standby-Modus auf die Audioverarbeitung hört, also die Möglichkeit der sprachbasierten Steuerung bietet. Außerdem erhalten wir eine Display-Steuerungs-Engine mit DSC-Unterstützung sowie den Microsoft Pluton-Prozessor, TPM-Funktionalität und SMU, um sicherzustellen, dass die Sicherheit kein Problem darstellt.
Die Strix Point SoC-Einheiten werden sowohl die oben erwähnte RDNA 3.5-basierte iGPU als auch die XDNA 2-basierte NPU erhalten. Der SoC selbst enthält auch einen 128-Bit-Speicher-Controller, der sowohl LPDDR5- als auch LPDDR5X-Speicherchips verarbeitet, aber auch klassischen Dual-Channel-DDR5-Speicher unterstützt. Der On-Board-PCIe-Hub stellt insgesamt 16 PCI-Express-4.0-Lanes zur Verfügung, was einen leichten Rückgang gegenüber den 20 Lanes der Phoenix-Serie bedeutet. Für Notebooks, die nicht über einen dedizierten FCH verfügen, stehen alle 16 Lanes zur Verfügung. Sollen diese SoC-Einheiten jedoch in eine Desktop-Umgebung migriert werden, werden 4 der 16 Lanes für die Kommunikation mit dem Chipsatz verwendet, so dass 12 Lanes zur Verfügung stehen. Im Falle von Phoenix bleiben 16 statt 12 Lanes aktiv.
Dies gilt natürlich nur für Sockel AM5 APUs, die später erscheinen werden. Ansonsten kann die dGPU-Sektion von Notebooks PCI Express 4.0 x8-Schnittstellen verwenden, und die verbleibenden Lanes können für M.2-Steckplätze oder zusätzliche Treiber "ausgegeben" werden. Die Plattform kann auch USB4-Anschlüsse mit 40 Gbit/s, zwei USB 3.2 Gen2x2-Anschlüsse mit 20 Gbit/s, zwei zusätzliche USB 3.2 Gen2-Anschlüsse mit 10 Gbit/s und drei USB 2.0-Anschlüsse verarbeiten.
Nachdem die Grundlagen geklärt sind, sehen wir uns an, welche Modelle das Unternehmen für die Markteinführung vorbereitet. Wie Sie aus der Tabelle unten ersehen können, stehen insgesamt drei Modelle für OEM-Partner zur Auswahl. Diese könnten also die Basis für die ersten RYZEN AI 300-basierten Notebooks sein.
Az AMD RYZEN AI 300-as sorozatának tagjai
| Modell/Feature | Anzahl der CPU-Kerne und Threads | CPU-Kerntakt | CPU-Boost-Taktfrequenz | L2-Cache | L3-Cache | iGPU | Speicher-Unterstützung | NPU | TDP-Rahmen |
| RYZEN AI 9 HX 375 (neu) | 4 ZEN 5, 8 ZEN 5 c; 24 Threads | 2 GHz | 5,1 GHz | 12 x 1 MB | 16 MB + 8 MB | Radeon 890M (16 CU) | LPDDR5-7500; DDR5-5600 | XDNA 2 (55 TOPs) | 15-54 W |
| RYZEN AI 9 HX 370 | 4 Stück ZEN 5, 8 Stück ZEN 5 c; 24 Threads | 2 GHz | 5,1 GHz | 12 x 1 MB | 16 MB + 8 MB | Radeon 890M (16 CU) | LPDDR5-7500; DDR5-5600 | XDNA 2 (50 TOPs) | 15-54 W |
| RYZEN AI 9 365 | 4 Stück ZEN 5, 6 Stück ZEN 5 c; 20 Fäden | 2 GHz | 5 Gigahertz | 10 x 1 MB | 16 MB + 8 MB | Radeon 880M (12 CU) | LPDDR5-7500; DDR5-5600 | XDNA 2 (50 TOPs) | 15-54 W |
Nach der Ankündigung sah es so aus, als würde die Familie mit einem Hochleistungsmodell, das für Gaming-Notebooks und DTR-Maschinen geeignet ist, und einem Modell mit bescheidener Leistung beginnen, aber vor kurzem wurde bekannt, dass die Familie um ein drittes Modell erweitert wird, das ebenfalls bald erhältlich sein wird. Da zum Zeitpunkt des Verfassens dieser Zusammenfassung bereits Informationen über das dritte Modell vorlagen, ist dieses ebenfalls in der Tabelle enthalten. Im Vergleich zu dem in der ersten Runde angekündigten Modell RYZEN AI 9 HX 370 unterscheidet sich das RZYEN AI 9 HX 375 dadurch, dass die an Bord befindliche NPU eine Spitzenleistung von 55 TOPs anstelle von 50 TOPs bietet, was einer Steigerung von 10% entspricht.
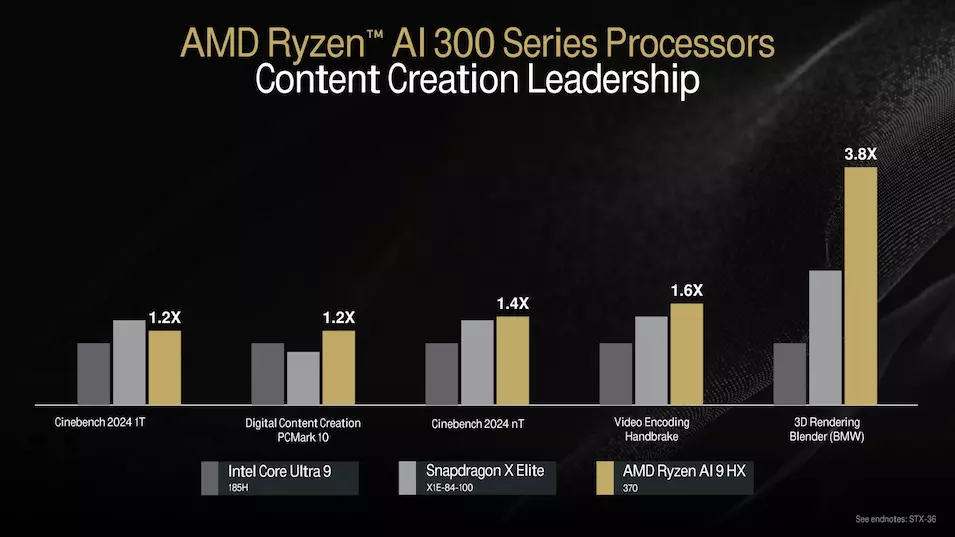
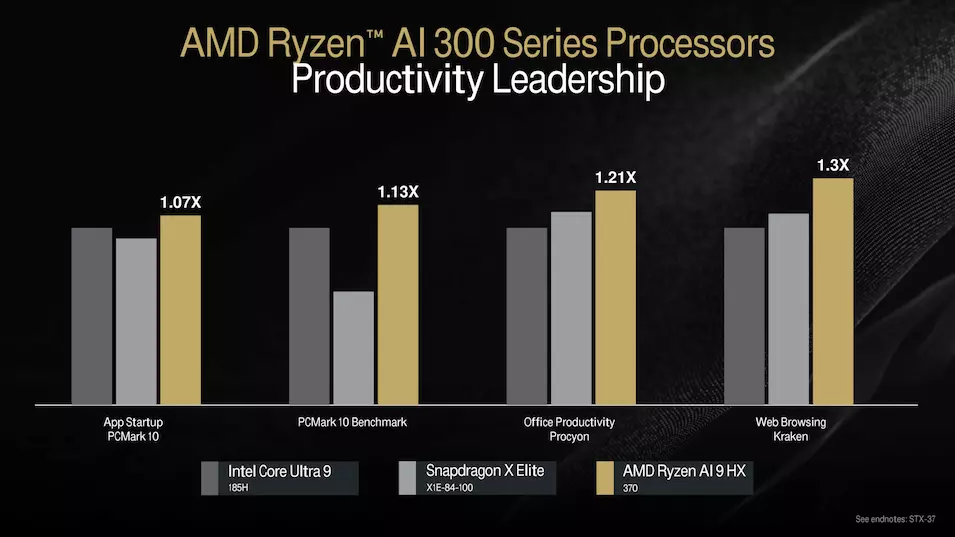
Es bleibt abzuwarten, wie sich die Neulinge gegen die Mitglieder der Lunar-Lake-Serie von Intel schlagen werden, die die Core-Ultra-200V-Serie verstärken werden. Natürlich hat das AMD-Team vorläufige Messungen durchgeführt, die zeigen werden, was das Spitzenmodell gegen Qualcomm Snapdragon X Elite und Intel Core Ultra 9 185H SoC-Einheiten tun kann. Die Galerie unten gibt Aufschluss darüber.
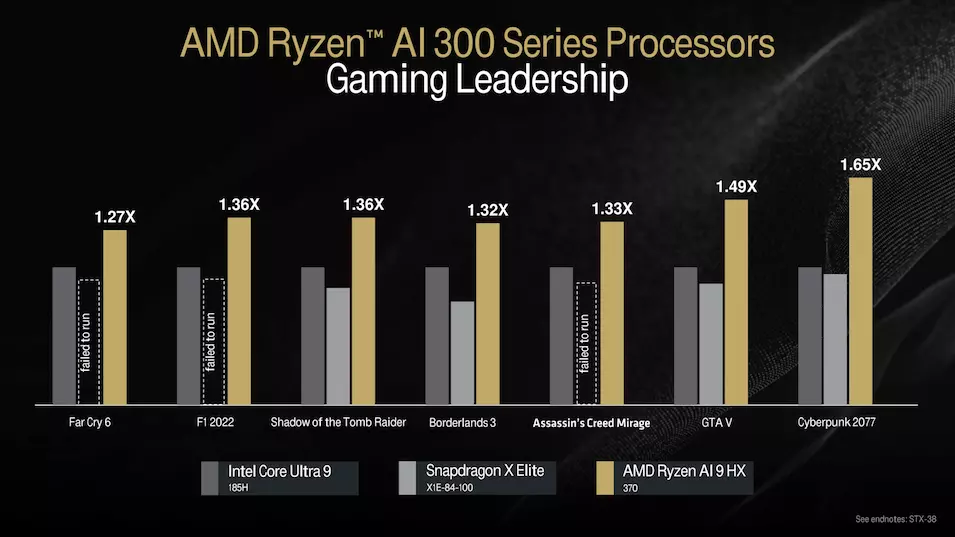
Basierend auf den internen Tests sieht das schnellste Mitglied der neuen mobilen APU-Serie recht vielversprechend aus, aber da der TDP-Rahmen in einem weiten Bereich eingestellt werden kann, wird die endgültige Leistung immer von der Flexibilität des SoC für das Notebook-Design abhängen, von der Kühlung bis zur Stromversorgung. Ein detailliertes Bild der Leistung jedes einzelnen Notebooks wird sich in den unabhängigen Tests ergeben, die derzeit veröffentlicht werden.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}